DelayGSE 一个基于 LLM 的语音增强(SE)模型。已经被 Interspeech2026 录用,这里有体验 Demo。我觉得真的效果还挺好的,其实我觉得这个的应用场景还是针对高需求用户的类似电影修复、音频修复。这个模型整体架构还是相对简洁的,整体是从 CosyVoice2 改过来的。思路其实很直接:把"文本到语音"换成"带噪语音到干净语音",让一个 Qwen2.5 的 LM 去预测干净语音的 DAC token,最后用 DAC 解码器还原波形。这一篇是离线版本(论文里的版本),下一篇 DelayGSE Part2 再记怎么把它改成流式上端。
先说说生成式 SE 的"老毛病":幻觉
传统的语音增强基本是两条路:要么估时频 mask、要么直接把带噪谱映射到干净谱,这类判别式方法的特点是稳——它不会无中生有,顶多噪声压不干净、或者把语音也压糊一点。后来 GAN 进来,训练目标从"逼近干净谱"变成"听起来自然",音质上了一个台阶。
再后来就是扩散模型和 LLM 这一套生成式方法。它们干的事不再是"把噪声减掉",而是去建模干净语音本身的分布,然后直接生成一段干净语音出来。好处很直接:感知质量能逼近录音棚级别,很多时候比判别式的天花板还高。
但生成式有个绕不开的代价——幻觉(hallucination)。在低信噪比、或者有瞬态噪声(敲击、咳嗽这种)的时候,模型会生成一段听起来很流利、但语义是错的、甚至根本不是原话的语音。已经有不少工作观察到这个现象:不管你用哪种生成策略、哪种语音表征,生成式 SE 的 WER(词错率)相比原始带噪语音常常不降反升。
说白了就是:音质上去了,但"说的对不对"掉下来了。DelayGSE 想解决的核心问题就是这个——既要生成式的音质,又不能让它"瞎说"。
现有的生成式 SE 大致分两类:一类在连续声学特征空间里做(比如 STFT 谱),思路借鉴图像里的扩散 / 概率流,把带噪语音当成一个被污染的观测,学一个从噪声分布反推回干净语音的过程,代表是 StoRM、FlowSE;另一类是离散 token 建模,把 SE 看成一个条件序列建模问题——带噪语音当条件,自回归或 mask 生成模型预测干净语音的 token,再解码成波形。DelayGSE 走的是第二条路。
整体框架
先看一眼整体结构:
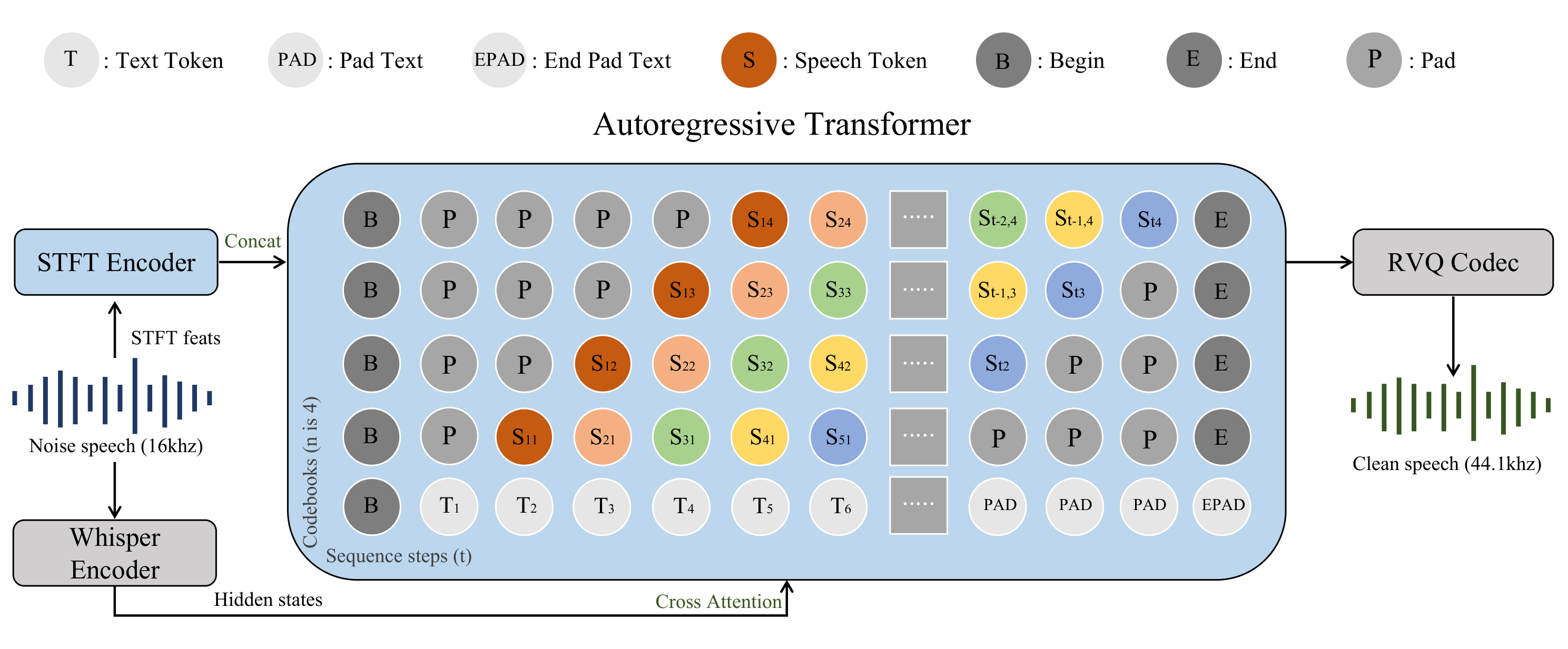
形式化一下,给一段退化波形 ,目标干净语音 先被 DAC 量化成一串离散 token \mathbf{z} = (z_1, \dots, z_T),模型学的是这个条件分布:
其中 是 STFT encoder(4 层 Conformer)出来的声学特征, 是冻结的 Whisper v3 (large) encoder 出来的语义特征。
这里有个双 encoder 的设计值得多说一句,注入方式还不一样:
- 声学特征 走 concat:直接跟 token embedding 拼起来喂进 Transformer。它带的是细粒度的频谱信息,负责"音色、细节像不像"。
- 语义特征 走 cross-attention:Whisper 是个 ASR encoder,它的表征天然带语义 / 音素信息。把它从 cross-attention 注入,相当于给 LM 一路"这句话大概在说什么"的提示,这是后面压制幻觉的一个重要支点。
输出侧,自回归 Transformer 把 token 一个个吐出来,最后交给 DAC 解码器还原波形 。
为什么用 44.1kHz 的 DAC
codec 的选择其实挺关键的。我们用的是 44.1kHz 的 Descript Audio Codec(DAC),理由有两个:
- 保高频。很多 codec 是 16kHz / 24kHz 的,超过 8 / 12kHz 的细节直接没了。但语音增强里高频细节(齿音、空气感)对"听感真实"影响很大,44.1kHz 才留得住。
- 统一 SE 和音频超分。我们的仿真数据里干净语音普遍在 24kHz 以上、很大一部分是 44.1kHz。直接在这个高码率的离散 token 空间里建模,意味着同一个模型既能做去噪 / 去混响,也能顺手做音频超分——输入是个 16kHz 的窄带带噪语音,输出可以是 44.1kHz 的宽带干净语音,框架不用改。
因为 codec 是 RVQ(残差矢量量化),有 个 codebook,所以上面那个条件分布要进一步拆成每个 codebook 的乘积:
就是第 步、第 个 codebook 的 token。多 codebook 怎么排预测顺序,就是下面 delay 要解决的事。
两个 Delay:让模型"先想清楚再开口"
DelayGSE 名字里的 “Delay” 来自两个互补的延迟策略:codebook-level delay 和 text-first multi-task delay。上面那张框架图里中间那块网格画的就是这两个 delay——纵向是各个 codebook、横向是时间步,token 沿对角线一步步错开。
Codebook-level delay:跨 codebook 的依赖
RVQ 的多个 codebook 之间是有依赖的——高层 codebook 是在低层残差上量化出来的,本来就该"看着低层来预测"。直接并行预测所有 codebook 会丢掉这层依赖,但严格串行又太慢。MusicGen 的做法是给各 codebook 加一个 stride-1 的固定延迟,让高层 codebook 在预测时能看到同一帧已经预测出来的低层 codebook:
注意条件里多了个 ——也就是当前帧、比自己低的那些 codebook。这套在 Parler-TTS、VoiceCraft 里都用过,本质是在"并行度"和"质量"之间取平衡。delay pattern 这个机制我之前单独写过一篇(Delay Pattern LLM),想深入的可以翻那篇。
Text-first delay:语义先行
第二个 delay 是这个工作压制幻觉的关键,灵感来自 Moshi 的 “inner monologue”。Moshi 做的是语音对话,但它先预测时间对齐的文本 token 作为中间的"语义草稿",再去生成声学 token——也就是把文本预测显式地排在声学预测前面,强行规定一个 “先语义、后声学(semantic-before-acoustic)” 的生成顺序。
DelayGSE 借了这个思路:先生成文本 token ,语音 token 整体延迟 步,于是联合分布拆成:
直觉上:让模型先把"这句话在说什么"想清楚(文本),再去填具体的声学细节。文本一旦定下来,它就像一根缰绳,约束着后面声学 token 不能跑偏——这正好掐住了"流利但说错"的幻觉。 的提前量是让声学预测在落笔时,已经能看到未来 5 步的文本。还有一点思考是,如果是很糟糕的场景,我们还可以人工给正确文本形成强约束(这里的文本不通过模型预测),我尝试下来如果真的是很大的噪声,人听不懂的情况下,模型会按照人工给的文本生成语音;如果是比较小的噪声,这时候人工给错误的文本,模型还是会依赖STFT的特征去生成,不会乱说。
训练目标
训练用 teacher forcing,整体是文本和声学的加权多任务交叉熵:
文本 loss 就是普通的 next-token CE:
每个语音 codebook 有自己的 CE,条件里同样带着当前帧低层 token 和提前 步的文本 :
是真值 token。。那个 (每个 codebook 的权重)不是拍脑袋设的,下一节专门讲。
Importance-aware:每个 codebook 不该一样重
RVQ 里有个常识:低层 codebook 更管"听不听得懂"(可懂度),高层 codebook 更管"听得好不好"(音质、音色)。既然各层贡献天差地别,训练时给它们一样的 loss 权重显然不合理——会让模型在不重要的高层上浪费容量,还容易引起梯度冲突。
所以我们提出一个 incremental contribution(增量贡献) 的办法去量化每层到底多重要,拿来当 loss 权重 :
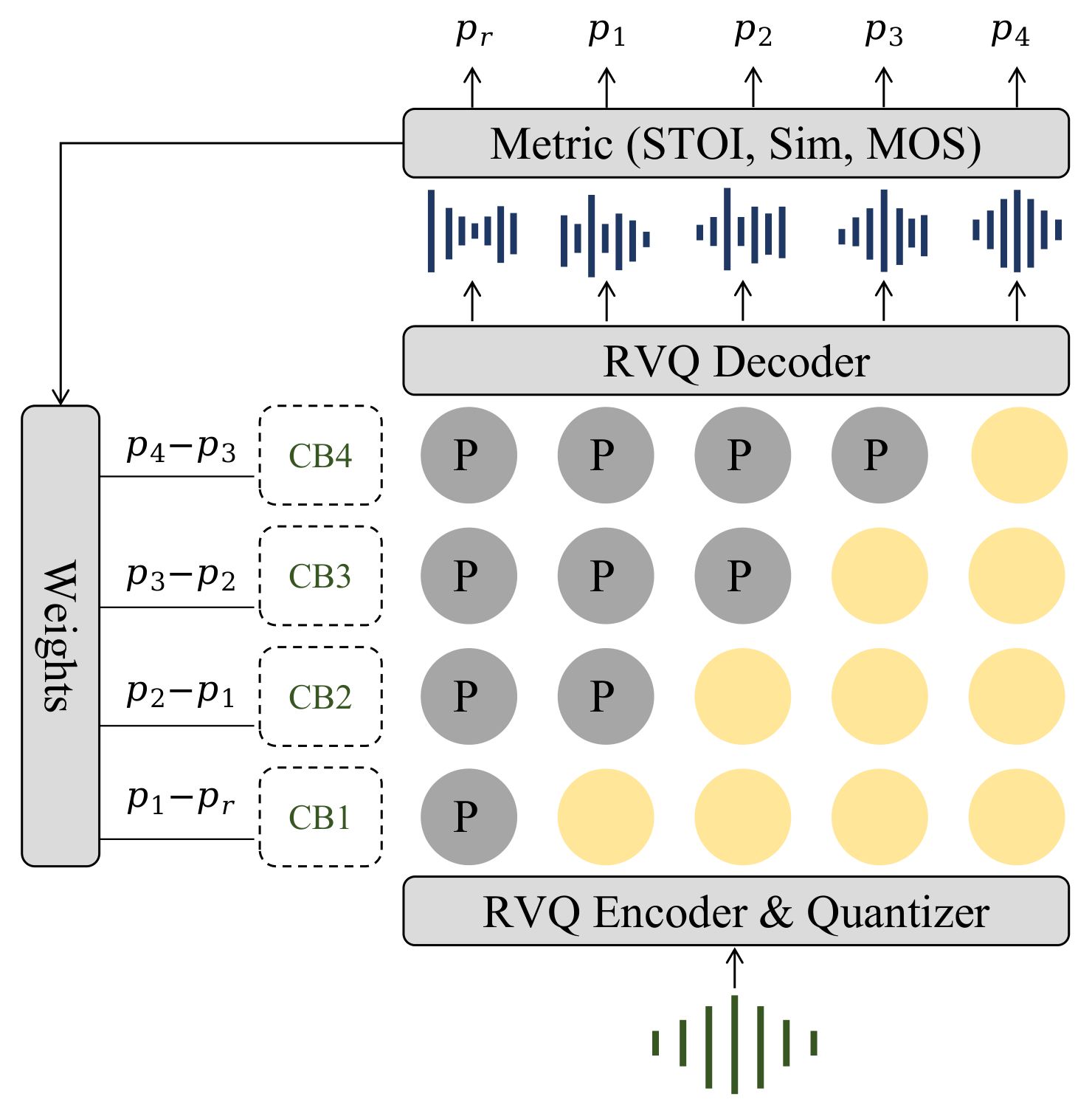
具体做法(对着上图看):
ps:其实这里画图我还是很用心的,可以仔细观察随机化token重构的音频波形图是乱的,随着逐层增加正确的token,音频波形越来越规整。😜
- 随机抽 10 万条 音频,编码成 层 RVQ;
- 先把所有层全随机化,解码出来算个 baseline 分数 (这时候基本啥也没保留);
- 然后从第 1 层开始逐层"解冻":保留前 层的真 code、其余层继续随机(图里灰色
P是保留的 GT、黄色是随机化的),解码、打分得到 ; - 第 层的重要性 = 它带来的增量提升 ;
- 在样本集上平均、归一化,就得到 。
打分用的是三个维度:感知质量(MOS)、可懂度(STOI)、说话人相似度(SIM),综合起来反映"这一层到底贡献了什么"。最后跑出来的权重是:
1 | w = [0.30, 0.13, 0.12, 0.10, 0.08, 0.09, 0.09, 0.06, 0.03] |
可以看到第一层(0.30)的权重远高于其它层,跟"低层最关键"的直觉完全吻合。这套权重的实际效果,在后面消融里会看到——它不光提质量,还加速收敛。
实验
数据 / 评测设置
- AR 模型:从 Qwen2.5 0.5B 初始化。输入带噪语音 16kHz,STFT 用 Hann 窗、
n_fft=512、hop=256,再过 4 层 Conformer encoder。Whisper encoder 冻结,STFT encoder 跟 AR 模型一起训。 - 优化:Adam,lr
5e-4,5000 步 warm-up + cosine 衰减,动态 batch(每个 batch 约 40s 音频),训 30 万步,只用 CE loss。 - 训练数据(仿真):干净语音 3 万+ 小时(In-house 中文为主,加 HiFi-TTS、LibriTTS-R),噪声约 600 小时(WHAM、FSD50K、自录会议噪声),另外仿了 70 万条混响样本(大 / 中 / 小会议室)。
- 评测集:DNS Challenge、VCTK-DEMAND、URGENT 2025(只取中英子集),外加一个内部会议室数据集 258 条——这个是真录的,覆盖近讲 / 3m / 5m / 8m 距离,安静 / 稳态噪声 / 瞬态噪声各种条件,是最贴近真实场景的硬骨头。
- 指标:感知质量用 DNSMOS P.808;可懂度用 WER(ASR 用 FireRedASR);说话人相似度 SIM 用 ERes2NetV2 提 embedding 算余弦。没用 PESQ 这类侵入式指标——它们要求波形严格对齐,对生成式模型不靠谱。
结果
对比对象覆盖了几条主流路线:GAN(自己训的 CMGAN-like 基线)、扩散(StoRM、FlowSE)、LLM(LLaSE-G1),以及 DelayGSE 自己的几个消融变体:
- DGSE-EW:Equal-Weight,所有 codebook loss 权重一样;
- DGSE-IW:Importance-Weight,用上面那套重要性权重;
- DGSE-IW+T:在 IW 基础上加延迟文本监督(text-aware);
- DGSE-IW+TG:IW+T 推理时额外喂真值文本(Ground-truth text)。
客观指标对比(MOS↑ / WER↓ / SIM↑,MOS 用 DNSMOS;NR = 无混响,WR = 有混响,RR = 真实录音):
| Model | Internal MOS | Internal WER | Internal SIM | VCTK MOS | VCTK WER | DNS WR | URGENT EN-WER | URGENT ZH-WER |
|---|---|---|---|---|---|---|---|---|
| Noise | 2.484 | 0.041 | 0.347 | 3.037 | 0.070 | 2.751 | 0.180 | 0.131 |
| GAN-based | 3.639 | 0.096 | 0.192 | 3.525 | 0.071 | 3.610 | 0.286 | 0.513 |
| StoRM | 3.353 | 0.724 | 0.131 | 3.592 | 0.074 | 3.142 | 0.371 | 0.572 |
| FlowSE | 3.255 | 0.147 | 0.244 | 3.564 | 0.079 | 3.298 | 0.334 | 0.305 |
| LLaSE-G1 | 3.817 | 0.411 | 0.250 | 3.526 | 0.121 | 3.951 | 0.353 | 0.507 |
| DGSE-EW | 4.007 | 0.120 | 0.298 | 3.728 | 0.086 | 4.087 | 0.242 | 0.191 |
| DGSE-IW | 4.043 | 0.099 | 0.344 | 3.738 | 0.072 | 4.146 | 0.218 | 0.156 |
| DGSE-IW+T | 4.040 | 0.063 | 0.324 | 3.726 | 0.066 | 4.117 | 0.196 | 0.143 |
| DGSE-IW+TG | 4.034 | 0.043 | 0.323 | 3.732 | 0.063 | — | 0.153 | 0.104 |
几个能拎出来的观察:
- GAN 稳但糊,感知质量明显追不上 LLM 类,细粒度建模能力有限;
- 扩散(StoRM / FlowSE) 在干净 / 弱噪下不错,但一上混响(WR)就掉得厉害,跨数据集不稳;
- LLaSE-G1 感知分很高,但 WER 明显偏高(Internal 0.411、URGENT-ZH 0.507)——典型的"重自然度、轻语义保真",也就是幻觉问题;
- DelayGSE(DGSE-IW) 是最均衡的:感知质量和音色相似度拿到最好或接近最好,同时各种条件下 WER 都有竞争力。这个均衡得益于离散多 codebook 表征——它把音素 / 词汇信息保得更好。
消融:每个设计到底值多少
- IW vs EW:重要性加权赢,因为它照顾了各层语义贡献的不均,也缓解了梯度冲突,质量和收敛都更好;
- 延迟文本监督(+T):WER 相对降低 15.8%。靠的就是那个"先语义后声学"的顺序——文本一旦定下,下游声学预测被约束住,幻觉被有效压制,而且对感知质量几乎没有损失;
- 喂真值文本(+TG):WER 相对降低 33.1%,这是在严重退化下可懂度恢复的一个上界;
- 另外用随机文本做了对照,结论很有意思:输入可靠的时候模型主要靠声学线索,只有在严重失真时才会去"听"文本——也就是文本这根缰绳是按需起作用的,不会在正常情况下喧宾夺主。
一些体会 / 总结
整篇做下来,我自己最受用的两点:
- 幻觉不是靠堆数据 / 堆参数能压住的,得在生成顺序上动刀。"先把语义想清楚再生成声学"这个 inductive bias,比单纯加监督有效得多——延迟文本带来的 15.8% 相对 WER 下降,几乎不花感知质量的代价,这个性价比很高。
- 多 codebook 不该一视同仁。用增量贡献去量化每层重要性、再回去配 loss 权重,这步看着工程,但它实打实地既提质量又加速收敛。
DelayGSE 把判别式的稳和 LLM 生成式的音质这两头接上了:用离散多 codebook + 延迟文本监督 + 重要性加权,在感知质量、鲁棒性、可懂度之间拿到了一个不错的折中。而且因为跑在 44.1kHz 的 DAC token 空间里,去噪、去混响、音频超分能装进同一个模型。
这一篇讲的是离线版本,重点在"为什么这么设计、效果如何"。下一篇 DelayGSE Part2 我会换个视角,记一下怎么把它做成流式——毕竟语音增强不能流式,基本就没法上端、没法实时通话。那篇会更偏工程:因果下采样的状态管理、滑动窗口 KV cache、delay pattern 的流式解码、以及 codec 解码器的流式化。