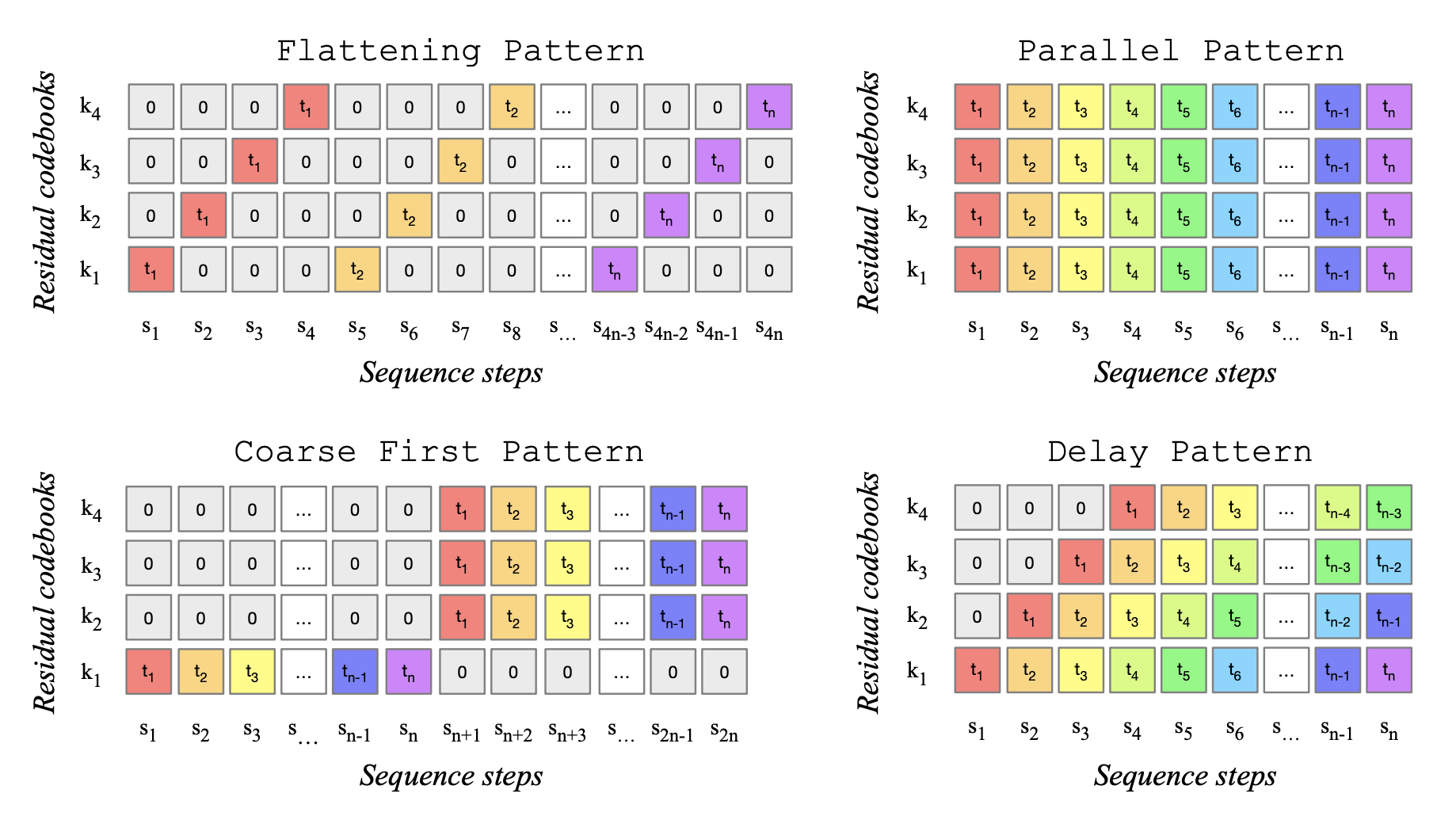
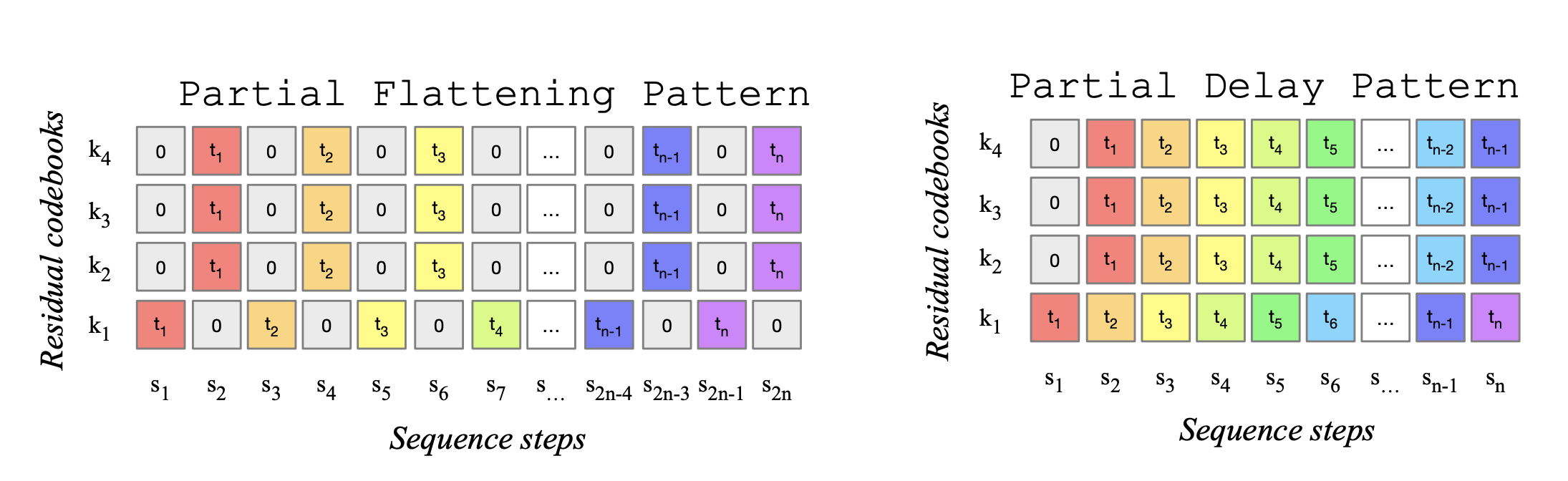
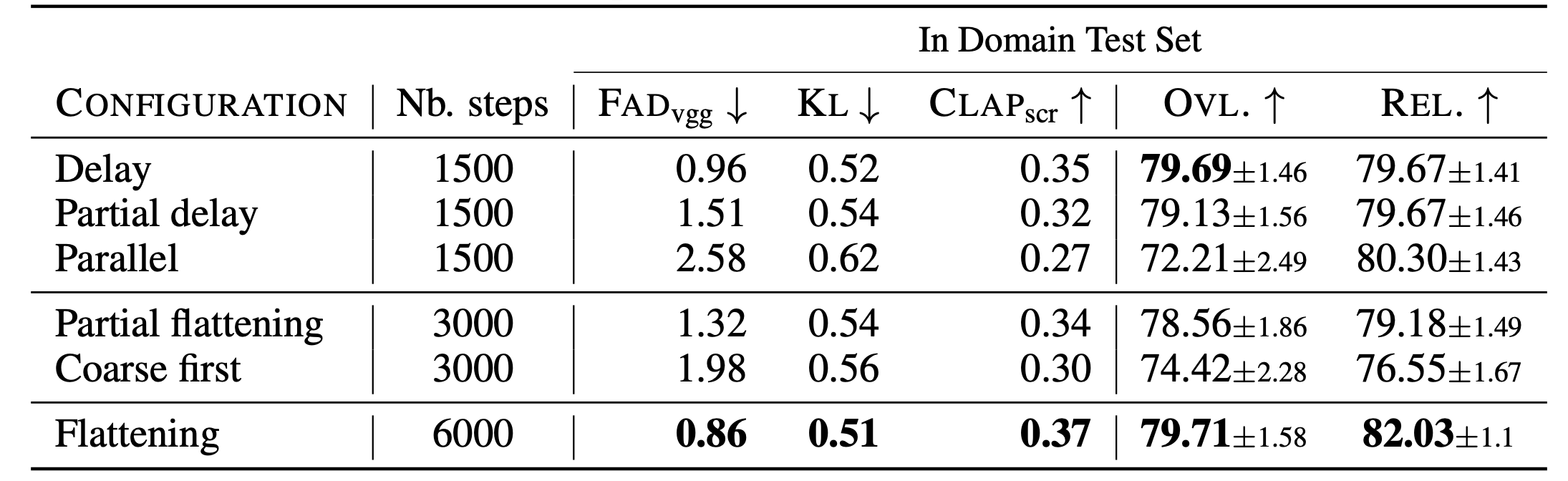
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
| def build_delay_pattern_mask(
self, input_ids: torch.LongTensor, bos_token_id: int, pad_token_id: int, max_length: int, num_codebooks: int
):
"""Build a delayed pattern mask to the input_ids. Each codebook is offset by the previous codebook by
one, giving a delayed pattern mask at the start of sequence and end of sequence. Take the example where there
are 4 codebooks and a max sequence length of 8, we have the delayed pattern mask of shape `(codebooks,
seq_len)`:
- [B, -1, -1, -1, -1, P, P, P]
- [B, B, -1, -1, -1, -1, P, P]
- [B, B, B, -1, -1, -1, -1, P]
- [B, B, B, B, -1, -1, -1, -1]
where P is the special padding token id and -1 indicates that the token is valid for prediction. If we include
a prompt (decoder input ids), the -1 positions indicate where new tokens should be predicted. Otherwise, the
mask is set to the value in the prompt:
- [B, a, b, -1, -1, P, P, P]
- [B, B, c, d, -1, -1, P, P]
- [B, B, B, e, f, -1, -1, P]
- [B, B, B, B, g, h, -1, -1]
where a-h indicate the input prompt (decoder input ids) that are offset by 1. Now, we only override the -1
tokens in our prediction.
"""
# (bsz * num_codebooks, seq_len) -> (bsz, num_codebooks, seq_len)
input_ids = input_ids.reshape(-1, num_codebooks, input_ids.shape[-1])
bsz, num_codebooks, seq_len = input_ids.shape
input_ids_shifted = torch.ones((bsz, num_codebooks, max_length), dtype=torch.long, device=input_ids.device) * -1
# we only apply the mask if we have a large enough seq len - otherwise we return as is
if max_length < 2 * num_codebooks - 1:
return input_ids.reshape(bsz * num_codebooks, -1), input_ids_shifted.reshape(bsz * num_codebooks, -1)
# fill the shifted ids with the prompt entries, offset by the codebook idx
for codebook in range(num_codebooks):
# mono channel - loop over the codebooks one-by-one
input_ids_shifted[:, codebook, codebook : seq_len + codebook] = input_ids[:, codebook]
# construct a pattern mask that indicates the positions of padding tokens for each codebook
# first fill the upper triangular part (the EOS padding)
eos_delay_pattern = torch.triu(
torch.ones((num_codebooks, max_length), dtype=torch.bool), diagonal=max_length - num_codebooks + 1
)
# then fill the lower triangular part (the BOS padding)
bos_delay_pattern = torch.tril(torch.ones((num_codebooks, max_length), dtype=torch.bool))
bos_mask = ~(bos_delay_pattern).to(input_ids.device)
eos_mask = ~(eos_delay_pattern).to(input_ids.device)
mask = ~(bos_delay_pattern + eos_delay_pattern).to(input_ids.device)
input_ids = mask * input_ids_shifted + ~bos_mask * bos_token_id + ~eos_mask * pad_token_id
# find the first position to start generating - this is the first place we have the -1 token
# and will always be in the first codebook (since it has no codebook offset)
first_codebook_ids = input_ids[:, 0, :]
start_ids = (first_codebook_ids == -1).nonzero()[:, 1]
if len(start_ids) > 0:
first_start_id = min(start_ids)
else:
# we have no tokens that need to be filled - return entire matrix of input ids
first_start_id = seq_len
# (bsz * num_codebooks, seq_len) -> (bsz, num_codebooks, seq_len)
pattern_mask = input_ids.reshape(bsz * num_codebooks, -1)
input_ids = input_ids[..., :first_start_id].reshape(bsz * num_codebooks, -1)
return input_ids, pattern_mask
def postprocess_dataset(self, labels):
bos_labels = torch.ones((labels.shape[0], self.num_codebooks, 1)) * self.start_mel_token
# (1, codebooks, seq_len)
# add bos
labels = torch.cat([bos_labels.to(labels.device), labels], dim=-1)
labels, delay_pattern_mask = self.build_delay_pattern_mask(
labels,
bos_token_id=self.start_mel_token,
pad_token_id=self.stop_mel_token,
max_length=labels.shape[-1] + self.num_codebooks,
num_codebooks=self.num_codebooks,
)
# the first ids of the delay pattern mask are precisely labels, we use the rest of the labels mask
# to take care of EOS
# we want labels to look like this:
# - [B, a, b, E, E, E, E]
# - [B, B, c, d, E, E, E]
# - [B, B, B, e, f, E, E]
# - [B, B, B, B, g, h, E]
labels = torch.where(delay_pattern_mask == -1, self.stop_mel_token, delay_pattern_mask)
# the first timestamp is associated to a row full of BOS, let's get rid of it
# we also remove the last timestampts (full of PAD)
# output = {"labels": labels[:, 1:]}
return labels[:, 1:]
|