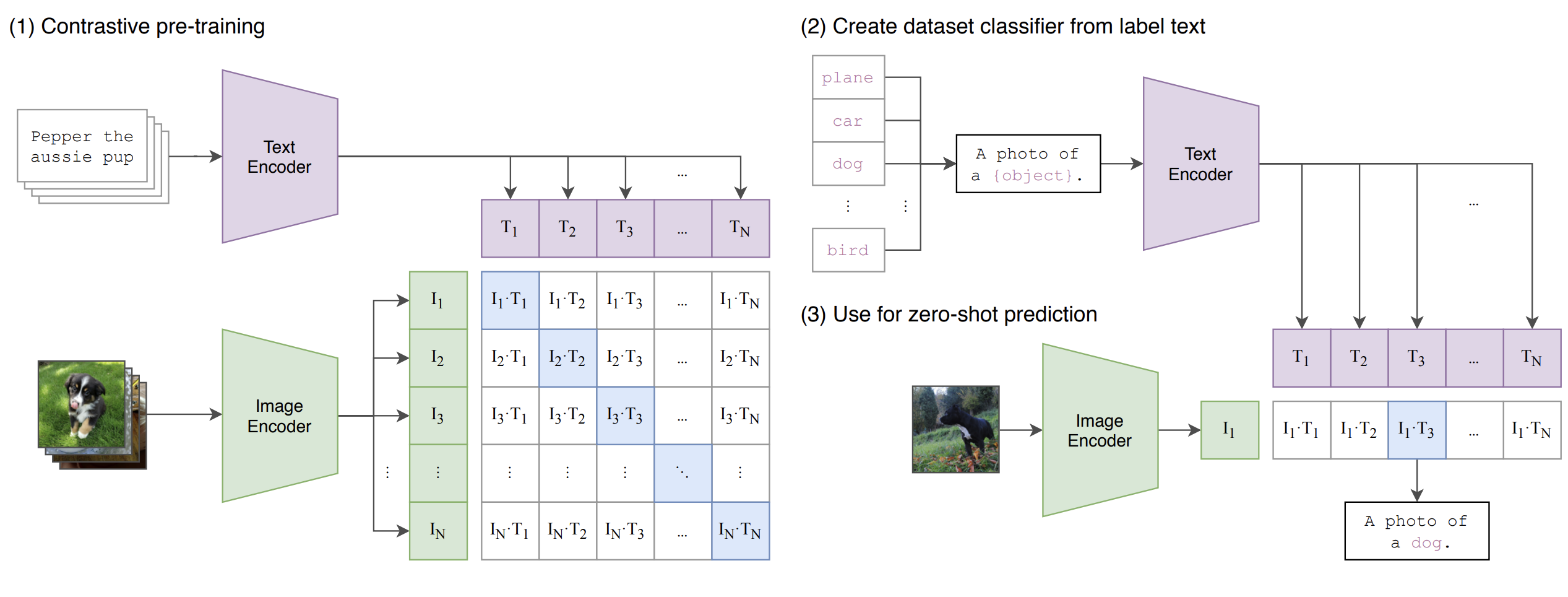
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
| class VoiceCLIP(nn.Module):
"""
CLIP model retrofitted for performing contrastive evaluation between tokenized audio data and the corresponding
transcribed text.
Originally from https://github.com/lucidrains/DALLE-pytorch/blob/main/dalle_pytorch/dalle_pytorch.py
"""
def __init__(
self,
*,
dim_text=512,
dim_speech=512,
dim_latent=512,
num_text_tokens=256,
text_enc_depth=6,
text_seq_len=120,
text_heads=8,
num_speech_tokens=8192,
speech_enc_depth=6,
speech_heads=8,
speech_seq_len=250,
text_mask_percentage=0,
voice_mask_percentage=0,
wav_token_compression=1024,
use_xformers=False,
clip_mels=False,
min_mel_size=10, # Default is approximately .5sec with default mel specs.
distributed_collect=False,
):
super().__init__()
# nn.Embedding
self.text_emb = mbnb.nn.Embedding(num_text_tokens, dim_text)
self.to_text_latent = mbnb.nn.Linear(dim_text, dim_latent, bias=False)
# nn.Embedding
self.speech_emb = mbnb.nn.Embedding(num_speech_tokens, dim_speech)
self.to_speech_latent = mbnb.nn.Linear(dim_speech, dim_latent, bias=False)
if use_xformers:
self.text_transformer = CheckpointedXTransformerEncoder(
needs_permute=False,
exit_permute=False,
max_seq_len=-1,
attn_layers=Encoder(
dim=dim_text,
depth=text_enc_depth,
heads=text_heads,
ff_dropout=.1,
ff_mult=2,
attn_dropout=.1,
use_rmsnorm=True,
ff_glu=True,
rotary_pos_emb=True,
))
self.speech_transformer = CheckpointedXTransformerEncoder(
needs_permute=False,
exit_permute=False,
max_seq_len=-1,
attn_layers=Encoder(
dim=dim_speech,
depth=speech_enc_depth,
heads=speech_heads,
ff_dropout=.1,
ff_mult=2,
attn_dropout=.1,
use_rmsnorm=True,
ff_glu=True,
rotary_pos_emb=True,
))
else:
self.text_transformer = Transformer(causal=False, seq_len=text_seq_len, dim=dim_text, depth=text_enc_depth,
heads=text_heads)
self.speech_transformer = Transformer(causal=False, seq_len=speech_seq_len, dim=dim_speech,
depth=speech_enc_depth, heads=speech_heads)
self.temperature = nn.Parameter(torch.tensor(1.))
self.text_mask_percentage = text_mask_percentage
self.voice_mask_percentage = voice_mask_percentage
self.wav_token_compression = wav_token_compression
self.xformers = use_xformers
self.clip_mels = clip_mels
self.min_mel_size = min_mel_size
self.distributed_collect = distributed_collect
if not use_xformers:
# nn.Embedding
self.text_pos_emb = mbnb.nn.Embedding(text_seq_len, dim_text)
# nn.Embedding
self.speech_pos_emb = mbnb.nn.Embedding(num_speech_tokens, dim_speech)
def embed_text(self, text):
text_mask = torch.ones_like(text.float()).bool()
text_emb = self.text_emb(text)
enc_text = self.text_transformer(text_emb, mask=text_mask)
text_latents = masked_mean(enc_text, text_mask, dim=1)
text_latents = self.to_text_latent(text_latents)
return text_latents
def forward(
self,
text,
speech_tokens,
return_loss=True
):
# print(f"text: {text}, speech_token: {speech_tokens}")
# print(f"text shape: {text.shape}, speech_token shape: {speech_tokens.shape}")
b, device = text.shape[0], text.device
if self.training:
if self.clip_mels:
margin = speech_tokens.shape[-1] - self.min_mel_size
speech_tokens = speech_tokens[:, :self.min_mel_size+randint(0,margin)]
voice_mask = torch.ones_like(speech_tokens.float()).bool() # Disable voice masking in this case.
else:
voice_mask = torch.rand_like(speech_tokens.float()) > self.voice_mask_percentage
text_mask = torch.rand_like(text.float()) > self.text_mask_percentage
else:
text_mask = torch.ones_like(text.float()).bool()
voice_mask = torch.ones_like(speech_tokens.float()).bool()
text_emb = self.text_emb(text)
speech_emb = self.speech_emb(speech_tokens)
if not self.xformers:
text_emb += self.text_pos_emb(torch.arange(text.shape[1], device=device))
speech_emb += self.speech_pos_emb(torch.arange(speech_emb.shape[1], device=device))
enc_text = self.text_transformer(text_emb, mask=text_mask)
enc_speech = self.speech_transformer(speech_emb, mask=voice_mask)
text_latents = masked_mean(enc_text, text_mask, dim=1)
speech_latents = masked_mean(enc_speech, voice_mask, dim=1)
text_latents = self.to_text_latent(text_latents)
speech_latents = self.to_speech_latent(speech_latents)
if self.distributed_collect:
collective = [torch.zeros_like(text_latents) for _ in range(torch.distributed.get_world_size())]
torch.distributed.all_gather(collective, text_latents)
collective[torch.distributed.get_rank()] = text_latents # For gradient propagation.
text_latents = torch.cat(collective, dim=0)
collective = [torch.zeros_like(speech_latents) for _ in range(torch.distributed.get_world_size())]
collective[torch.distributed.get_rank()] = speech_latents # For gradient propagation.
torch.distributed.all_gather(collective, speech_latents)
speech_latents = torch.cat(collective, dim=0)
b = text_latents.shape[0]
text_latents, speech_latents = map(lambda t: F.normalize(t, p=2, dim=-1), (text_latents, speech_latents))
temp = self.temperature.exp()
if not return_loss:
sim = einsum('n d, n d -> n', text_latents, speech_latents) * temp
return sim
sim = einsum('i d, j d -> i j', text_latents, speech_latents) * temp
labels = torch.arange(b, device=device)
loss = (F.cross_entropy(sim, labels) + F.cross_entropy(sim.t(), labels)) / 2
return loss
|