VQGAN:将图像压缩成离散Token,同时保留图像的绝大部分信息。将VQGAN作用到Mel谱中可以做到更极致压缩;帧率可以控制在 10 左右。LLM可以建模更长的音频。
VQ-VAE
比较详细的 VQVAE 的解读:轻松理解 VQ-VAE:首个提出 codebook 机制的生成模型
需要理解的有两点:
- 由于 VQ 的存在导致了中间不可导,不能直接利用重构损失优化 Encoder。通过 preserve gradients 的技巧可以完成梯度的传递,具体:
1 | z_q = z + (z_q - z).detach() |
- 优化 CodeBook 的损失有两部分,具体:
其中,第一个损失仅用于优化 CodeBook,目标是使得所选的矢量尽可能接近编码器的输出。第二个损失用于优化编码器,目标是让编码器的输出尽可能接近矢量,beta参数控制重要性。在实际中算法对beta不敏感。实际算法实现有两种方式:
- 显示计算两个 loss:
1 | loss = torch.mean((z_q.detach()-z)**2) + self.beta * \ |
- 利用 ema updates 方式,实际仅计算第二个损失:
1 | diff = (quantize.detach() - input).pow(2).mean() |
VQGAN
VQGAN 主要是在 VQ-VAE 的基础上引入了 GAN 的方式进行训练,使得解码出来的图像细节更丰富。除了对抗损失之外,还有一个特征匹配损失(利用预训练的VGG计算)。
代码一目了然
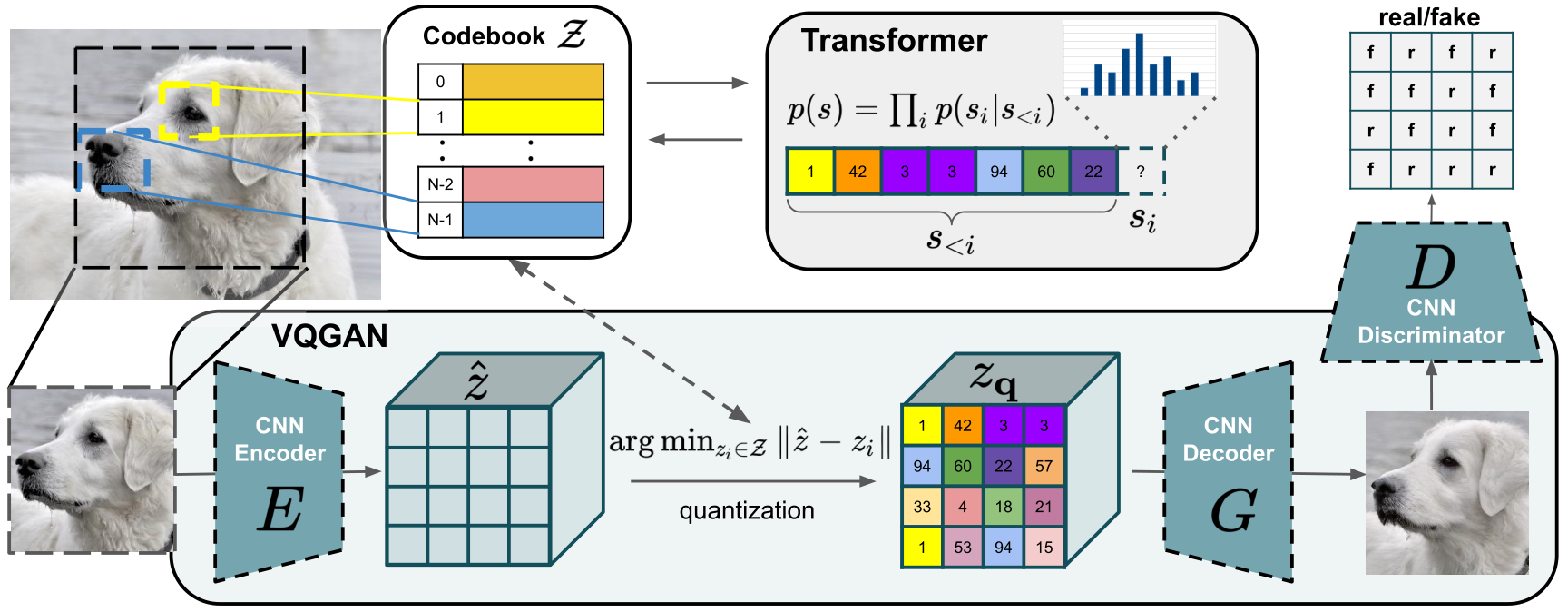
SpecVQGAN
在 VQGAN 没出来多久就有人把它用在了语音领域,可以参考。
https://github.com/v-iashin/SpecVQGAN
在实际实现过程中可以把特征匹配损失利用whisper的encoder替换vgg。
还有一些最近的值得借鉴的工作,如 VQGAN-LC、Music2Latent
总结
核心的概念就是压缩,不管压缩到离散的矢量还是连续的latent。当压缩的足够才能更高效的训练、推理自回归模型。