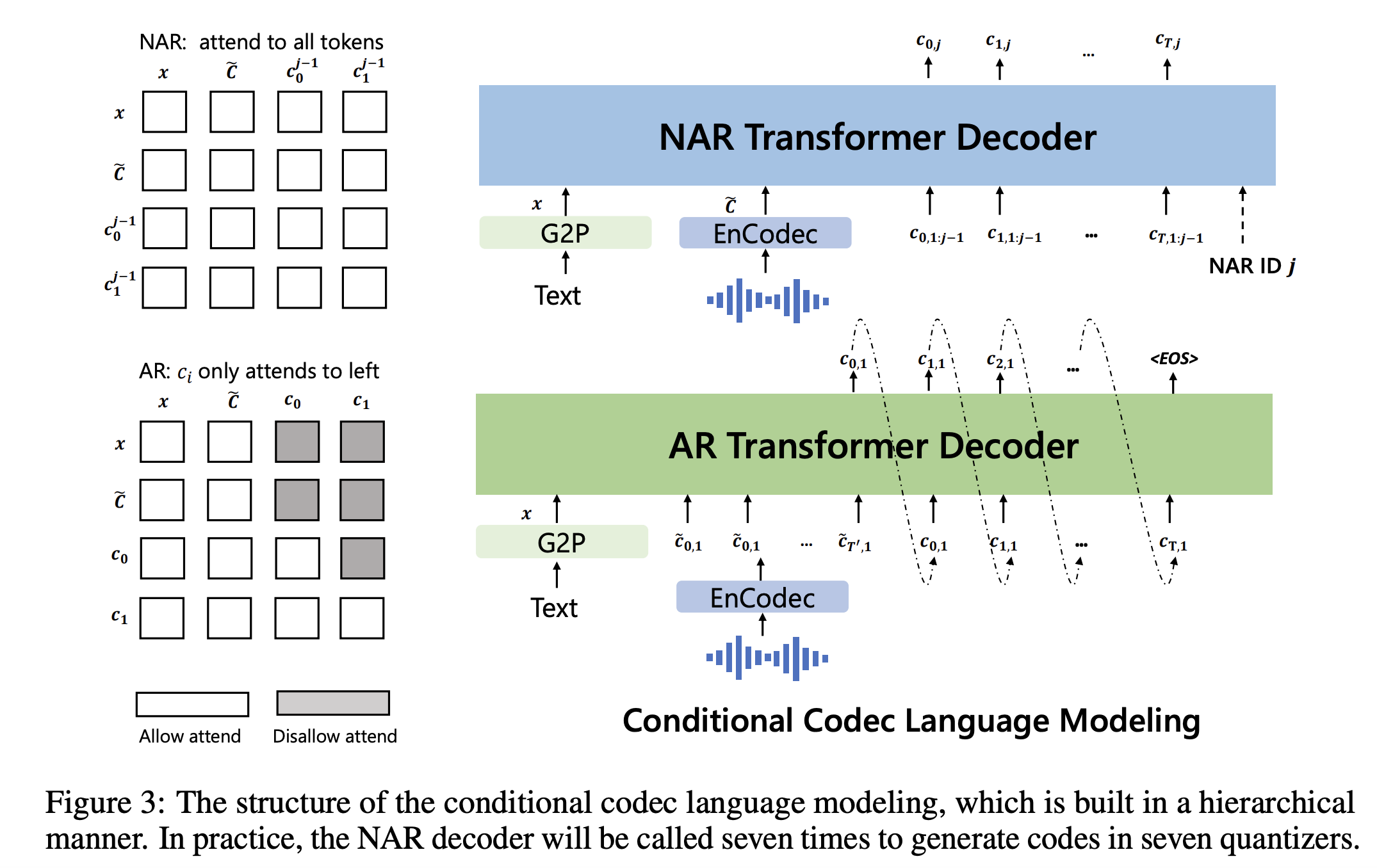
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers: 想法和思路与 AudioLM 类似,就是将 Semantic tokens 生成的过程换成了文本输入。然后利用几秒的提示语音获得声学特征,包括音色、韵律、背景环境等。这样就可以做 zero-shot 的语音生成了。VALL-E 利用 EnCodec 作为离散 token 提取和解码模型。VALL-E 有一些后续工作,包括多语音版本VALL-E X,多任务版本Speech X。
Paper
论文:https://arxiv.org/abs/2301.02111
代码
没有官方代码,网上复现的有
细节解读
框架图如下:
- 主体框架
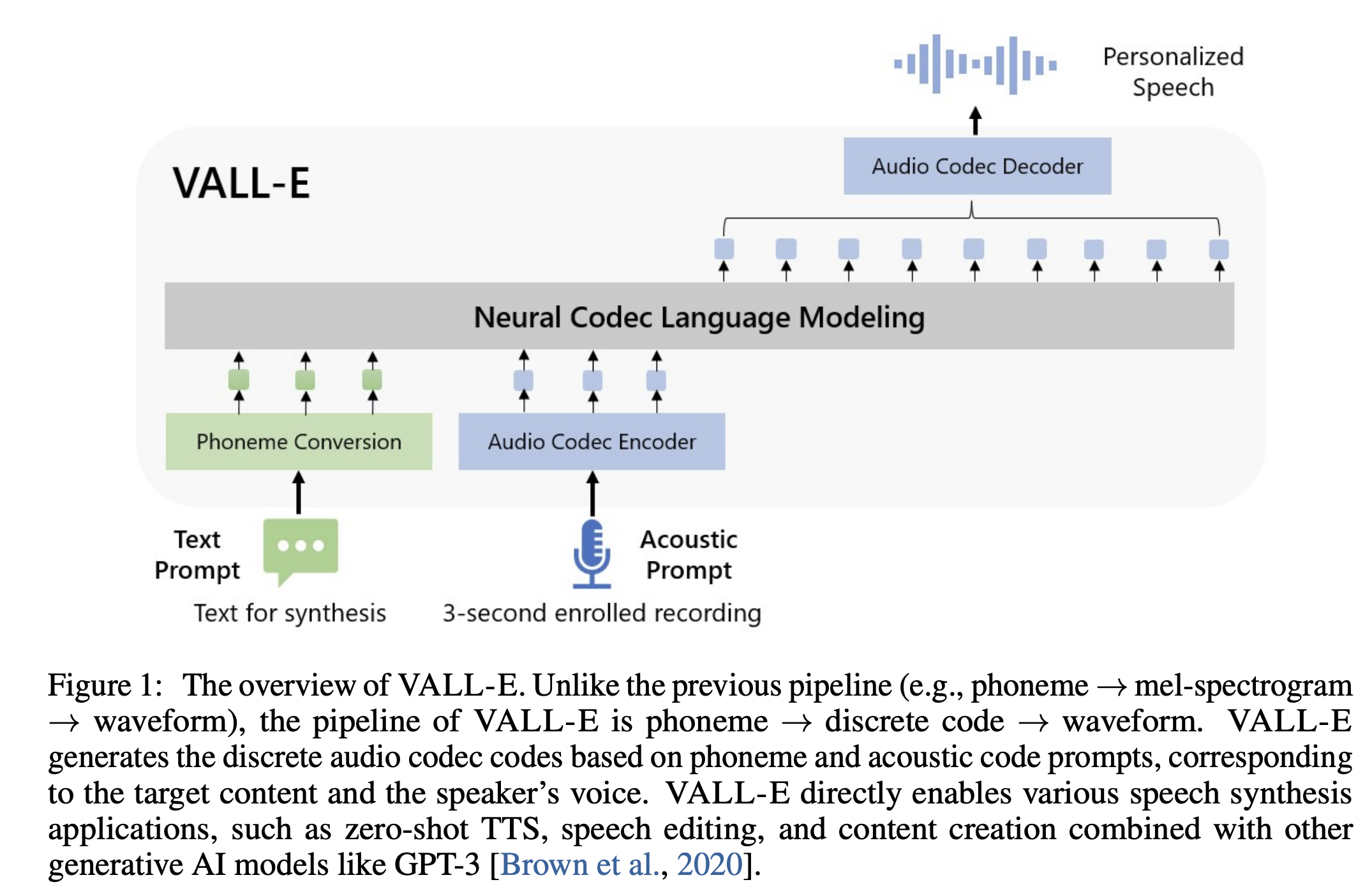
- RVQ框架
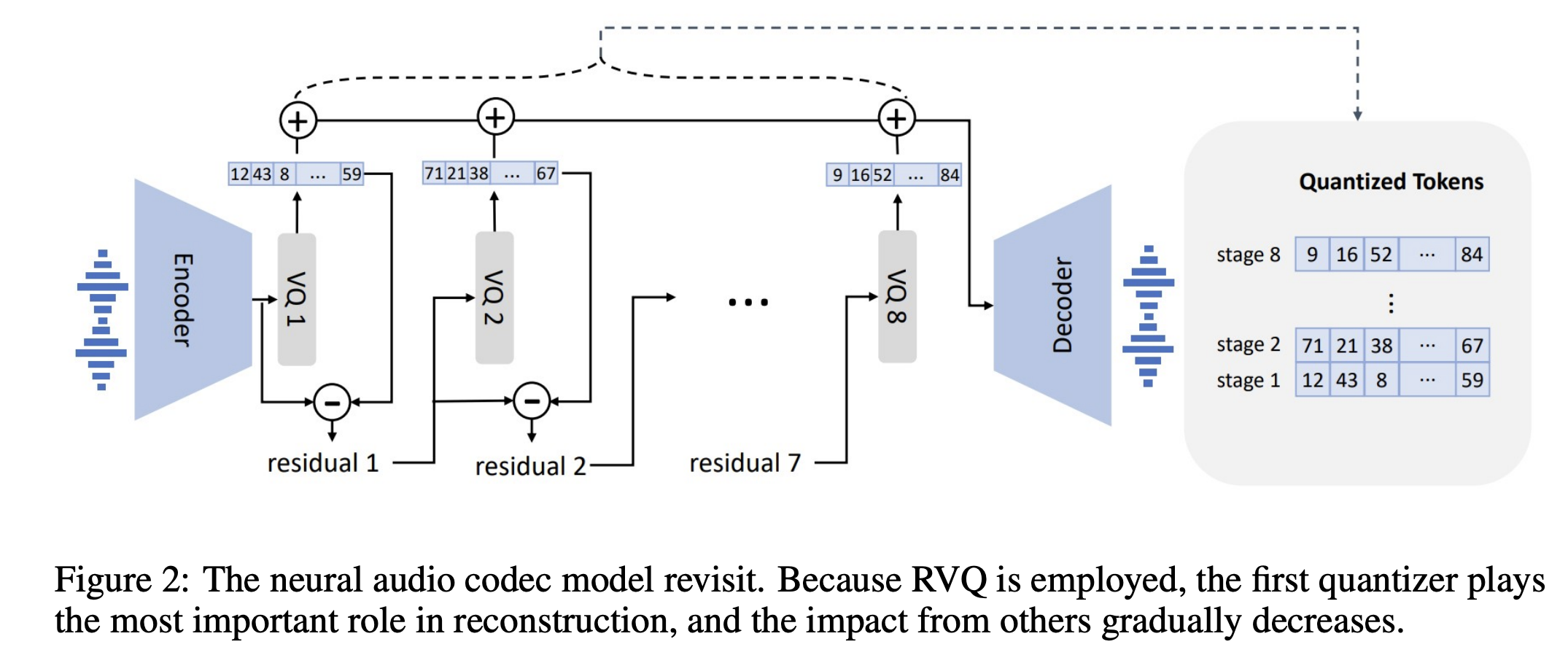
- VALLE分层结构