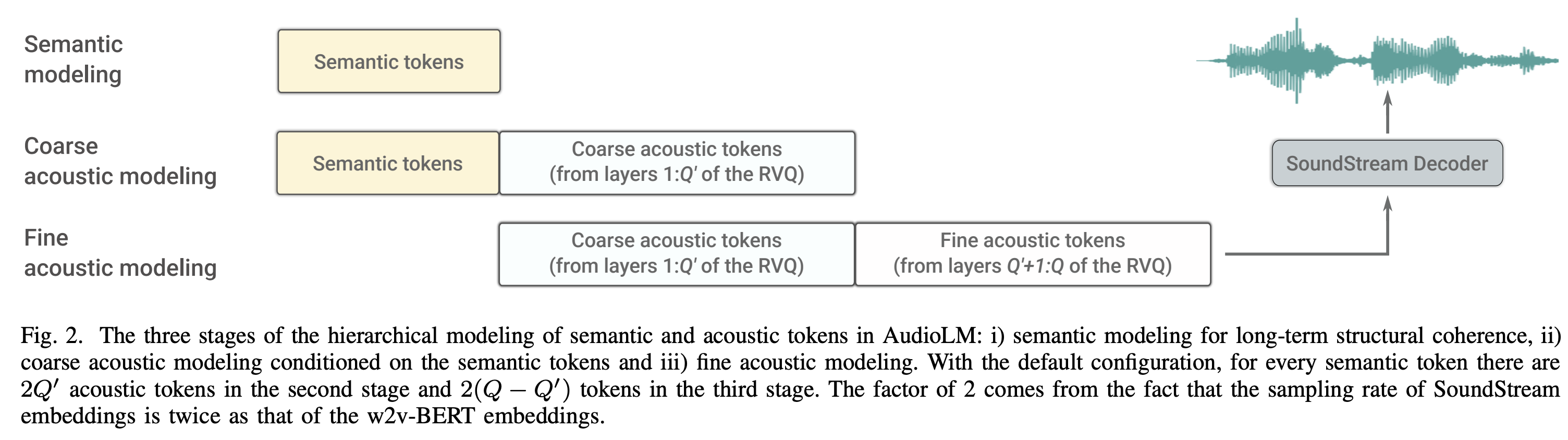
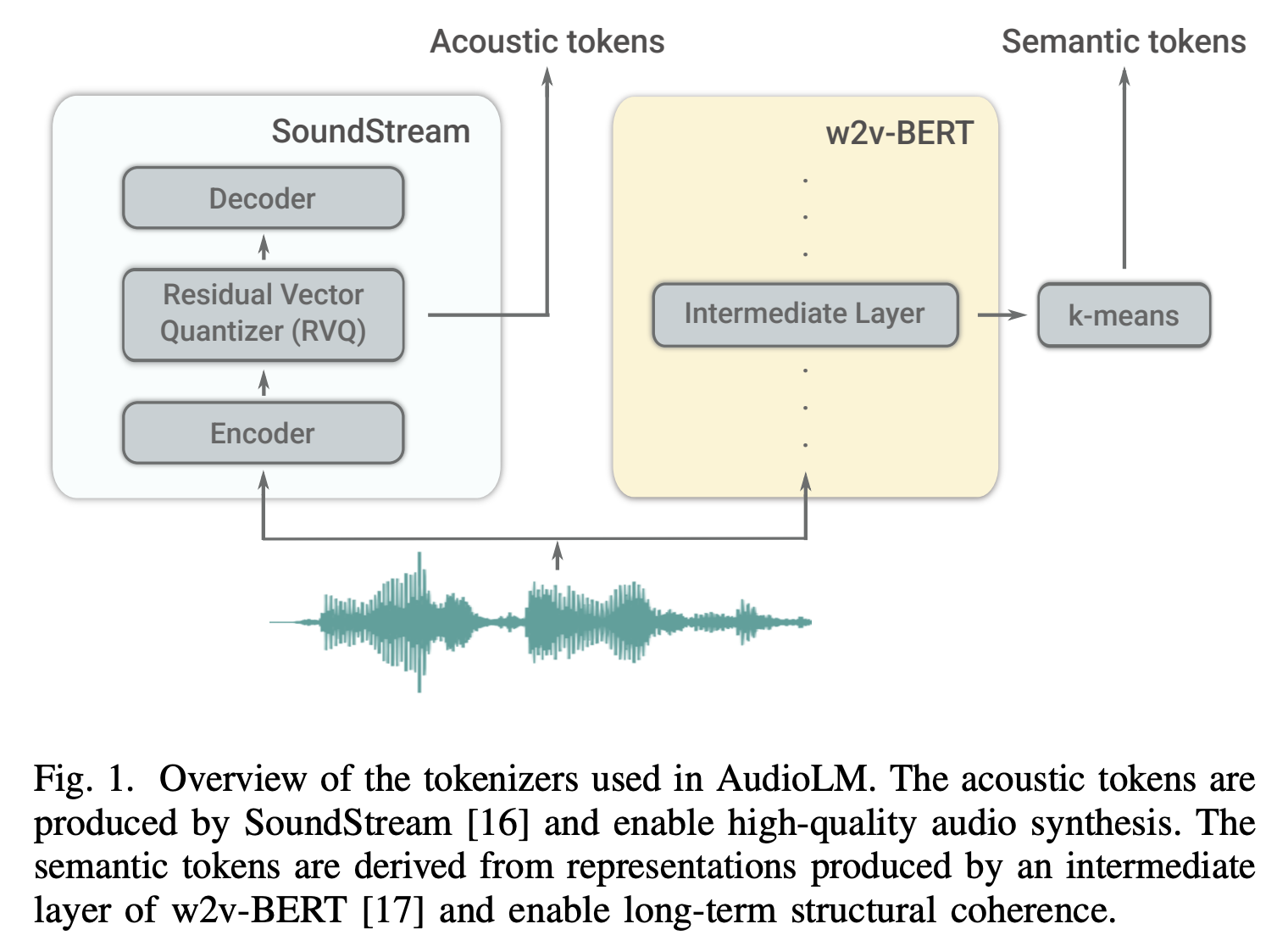
AudioLM: a Language Modeling Approach to Audio Generation: 利用 LLM 的思路对语音建模,目的是可以语音续写(就是给一个几秒的语音 Prompt,然后按照这个提示往后续写),实验下来不仅可以进行语音续写,还可以进行钢琴🎹曲的续写。模型主要利用了两个离散化方法,分别是通过 SoundStream 获得 Acoustic tokens,通过 w2v-BERT 获得 Semantic tokens。Semantic token 主要保证续写的长期结构,主要是可懂度; Acoustic token 主要保证续写的声学特征,主要是音色、韵律、背景环境这种。
Paper
论文:https://arxiv.org/abs/2209.03143
代码
细节解读
框架图如下:
- 获取离散 tokens
- 主体模型