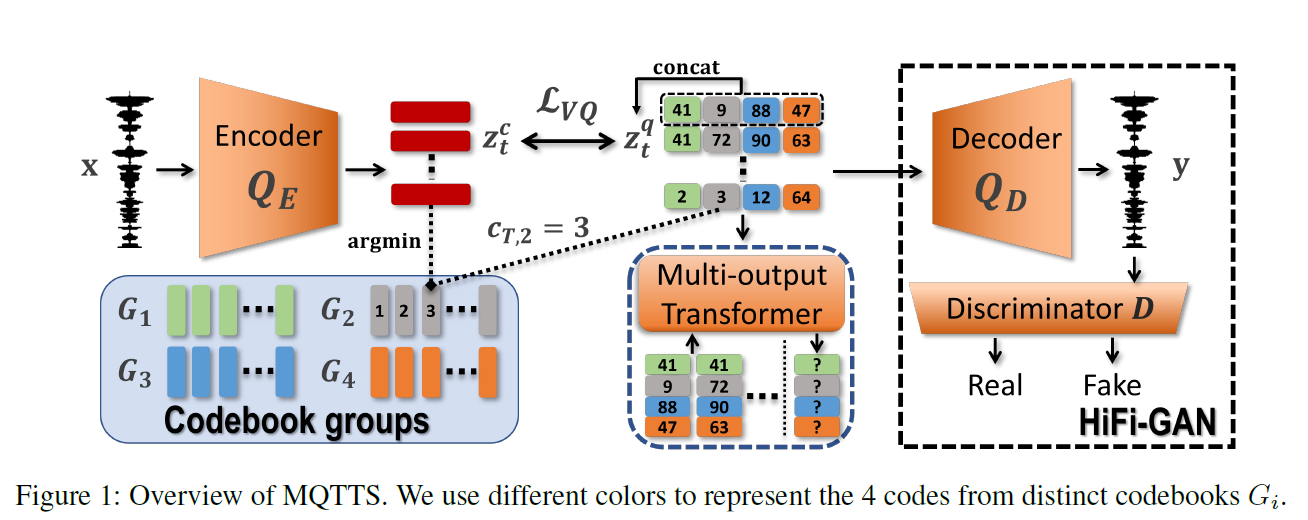
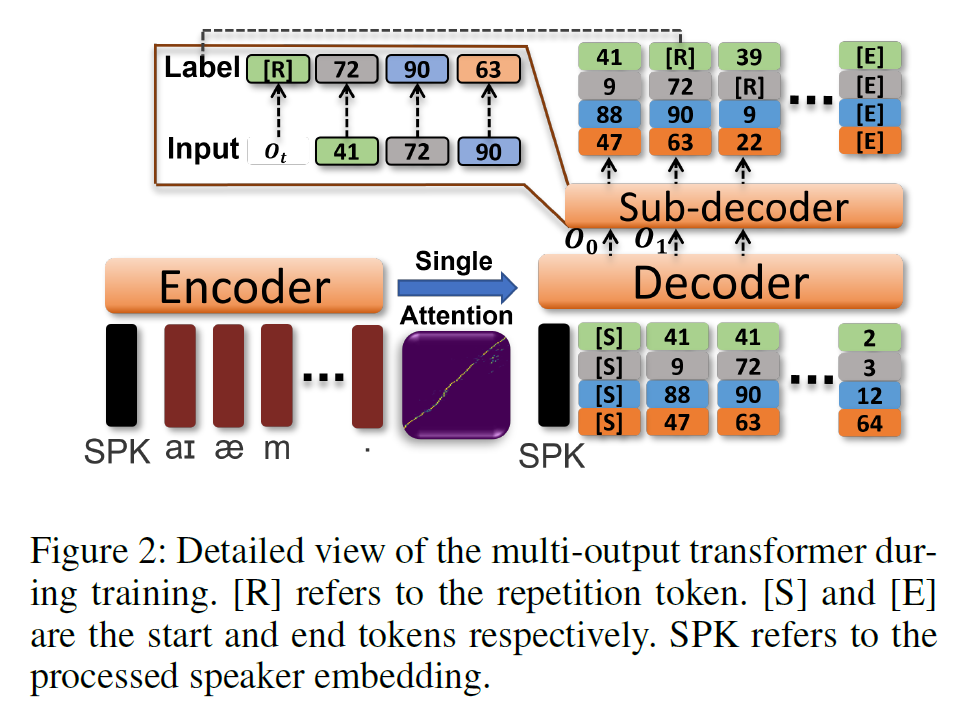
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
| def inference_topkp_sampling_batch(self, phone, spkr, phone_mask, prior=None, output_alignment=False):
batch_size = phone.size(0)
final_outputs = [0 for _ in range(batch_size)]
spkr = self.layer_norm_spkr(spkr.unsqueeze(1))
inp = self.layer_norm(self.transducer.start_token(phone.device)) #1, 1, C
# print(inp)
# print(inp.shape) # [1, 1, 768]
# start_token 是 161
inp = inp.expand(batch_size, -1, -1) #N, 1, C
inp = torch.cat([spkr, inp], 1)
# 嵌入 spkr
prior_size = 0
if prior is not None:
prior = self.transducer.encode(prior)
prior = self.layer_norm(prior)
prior_size = prior.size(1)
inp = torch.cat([inp, prior], 1)
# 加入静音片段作为 Prompt
phone = self.encode_phone(phone, spkr, phone_mask)
tgt_mask = self.tgt_mask[:inp.size(1), :inp.size(1)].to(inp.device)
inps = inp
#Decode
past_kvs1, past_kv_cross, past_kvs2, clusters = None, None, None, torch.empty([batch_size, 0, self.hp.n_cluster_groups], device=phone.device, dtype=torch.long)
audio_alibi = self.alibi(inp)
audio_alibi[:, 0] = 0
audio_alibi[:, :, 0] = 0
back_map = torch.zeros([batch_size, 1], device=phone.device, dtype=torch.long)
# 和 batch_size 为行的 0 向量
length_counter = torch.zeros([batch_size], device=phone.device, dtype=torch.long)
real_phone_lengths = (~phone_mask).long().sum(-1) #N,
if output_alignment:
assert batch_size == 1, "Now only support output alignment for bs = 1 for debugging issues..."
alignment = torch.zeros((1, self.hp.max_output_length, self.hp.max_output_length), device=phone.device)
for i in range(self.hp.max_output_length):
cond, _, _, new_1 = self.decoder(inp, memory=None, attn_bias=audio_alibi, tgt_mask=tgt_mask, past_kvs=past_kvs1)
# cond.shape: [B, 5, 768], 5 分别是 spk, 开始token 和 3个 Prompt
#Only feed in the current frame and the next frame attending!
t_length, c_length = phone.size(1), phone.size(2) # T, C=768
selected_phone = phone.reshape(-1, c_length) #N*T, C
index_map = torch.arange(self.hp.phone_context_window, device=phone.device) # [0, 1, 2]
index_map = back_map[:, -1:] + index_map.repeat(batch_size, 1)
# back_map 最后一列 + index_map
# 这里应该是求 单调对齐的
add = torch.arange(batch_size, device=index_map.device).unsqueeze(1) #N, 1
index_map = index_map + add * t_length # 由于处理过程中将 batch 拉平了,所以 index 需要特殊处理
index_map = index_map.reshape(-1) #N * 3 # phone 是被拉长了的!
selected_phone = selected_phone[index_map].reshape(batch_size, self.hp.phone_context_window, c_length) #N*3, C
#Mask for the starting phones
phone_mask = torch.arange(self.hp.phone_context_window, device=phone.device).repeat(batch_size, 1)
phone_mask = (phone_mask <= (back_map[:, -1:] + 1).expand(-1, self.hp.phone_context_window))
phone_mask = ~phone_mask
cond, _align = self.aligner(cond, selected_phone, tgt_mask=tgt_mask, memory_key_padding_mask=phone_mask)
# 仅仅利用部分 phone 进行计算,不需要全局的!
cond = cond[:, -1].unsqueeze(1) #N, 1, C
#Run sub-decoder inference
output = []
for j in range(self.hp.n_cluster_groups):
# 循环预测每一个码本的矢量
q_input = torch.cat(output, 1) if j else None
logit = self.transducer.decoder.infer(cond, q_input) #N, n_codes , 9, 163
#Block Start Token
logit[:, self.hp.n_codes + 1] = -float("Inf") # 删除没用的标识符号
#Don't output stop token if alignment not near end
# print(real_phone_lengths)
logit_tmp = logit[back_map[:, -1] < (real_phone_lengths - 2)]
# print(back_map)
# print(logit_tmp.shape)
# raise OSError('end')
logit_tmp[:, self.hp.n_codes] = -float("Inf")
logit[back_map[:, -1] < (real_phone_lengths - 2)] = logit_tmp
#Repetition penalty
if self.hp.use_repetition_token and self.hp.repetition_penalty != 1.0:
logit[:, self.hp.n_codes + 2] /= self.hp.repetition_penalty
if self.hp.use_repetition_gating:
logit[:, self.hp.n_codes + 2] = torch.min(torch.max(logit[:, :self.hp.n_codes]), logit[:, self.hp.n_codes + 2])
#Top_p
if self.hp.top_p < 1.0 and self.hp.top_p > 0.0:
sorted_logits, sorted_idxs = torch.sort(logit, descending=True)
cum_probs = torch.cumsum(torch.softmax(sorted_logits, dim=-1), dim=-1)
additional_prob = (self.hp.length_penalty_max_prob - self.hp.top_p) * (length_counter / self.hp.length_penalty_max_length)
idx_to_remove = cum_probs > (self.hp.top_p + additional_prob).unsqueeze(-1)
idx_to_remove[:, :self.hp.min_top_k] = False
idx_to_remove = idx_to_remove.scatter(1, sorted_idxs, idx_to_remove)
logit[idx_to_remove] = -float("Inf")
#Sampling
probs = torch.softmax(logit / self.hp.sampling_temperature, dim=-1)
idx = torch.multinomial(probs, 1) #N, 1
#If is repetition token
if self.hp.use_repetition_token:
if clusters.size(1) == 0: #First token, random choice
idx[idx==(self.hp.n_codes + 2)] = torch.randint(self.hp.n_codes, size=(1,), device=idx.device)
else:
idx[idx==(self.hp.n_codes + 2)] = clusters[:, -1:, j][idx==(self.hp.n_codes + 2)]
output.append(idx)
output = torch.cat(output, 1).unsqueeze(1) #N, 1, n_groups
# output: t=1 时刻的矢量
#Stop criterion
stopping_streams = (back_map[:, -1] == (real_phone_lengths - self.hp.phone_context_window))
stopping_streams = (stopping_streams & self.transducer.is_end_token_batch(output)) | (stopping_streams & (torch.argmax(_align[:, 0, -1], dim=-1) == self.hp.phone_context_window - 1)) #N,
if i == self.hp.max_output_length - 1:
stopping_streams[:] = True
stopping_streams_idx = np.where(stopping_streams.detach().cpu().numpy())[0]
num_stopped = stopping_streams.long().sum().item()
if num_stopped > 0:
stopped = clusters[stopping_streams]
n_seats, stop_seats = 0, 0
for n_s, seat in enumerate(final_outputs):
if type(seat) == int:
n_seats += 1
if n_seats - 1 in stopping_streams_idx:
# print (n_seats, stopping_streams_idx, stopped.size(), stop_seats)
final_outputs[n_s] = stopped[stop_seats]
stop_seats += 1
n_remained = sum([int(type(x) == int) for x in final_outputs])
if n_remained == 0:
break
#Trim batches
batch_size = batch_size - num_stopped
output = output[~stopping_streams]
phone = phone[~stopping_streams]
real_phone_lengths = real_phone_lengths[~stopping_streams]
clusters = clusters[~stopping_streams]
back_map = back_map[~stopping_streams]
length_counter = length_counter[~stopping_streams]
_align = _align[~stopping_streams]
news = [inps] + new_1
inps = inps[~stopping_streams]
for layer in range(len(news)):
news[layer] = news[layer][~stopping_streams]
if past_kvs1 is not None:
for layer in range(len(past_kvs1)):
past_kvs1[layer] = past_kvs1[layer][~stopping_streams]
#Update args
tgt_mask = self.tgt_mask[i+3+prior_size, :i+3+prior_size].to(phone.device).unsqueeze(0)
audio_alibi = self.alibi(tgt_mask)[:, -1].unsqueeze(1)
audio_alibi[:, :, 0] = 0
if output_alignment:
alignment[:, i, back_map[0, -1]: back_map[0, -1]+self.hp.phone_context_window] = _align[:, 0, -1].unsqueeze(0)
next_idx = (_align[:, 0, -1, 0] < (1 / self.hp.phone_context_window)).long()
next_idx[length_counter >= self.hp.length_penalty_max_length] = 1
new_bk = torch.minimum(back_map[:, -1] + next_idx, real_phone_lengths - self.hp.phone_context_window)
back_map = torch.cat([back_map, new_bk.unsqueeze(1)], 1)
length_counter[next_idx == 0] += 1
length_counter[next_idx != 0] = 0
if i == 0:
past_kvs1 = news[:self.hp.dec_nlayers]
else:
news = [x[:, -1:] for x in news]
for ii, (p, n) in enumerate(zip(past_kvs1, news[:self.hp.dec_nlayers])):
past_kvs1[ii] = torch.cat([p, n], 1)
inp = self.transducer.encode(output)
inp = self.layer_norm(inp)
inps = torch.cat([inps, inp], 1)
clusters = torch.cat([clusters, output], 1) #N, T, 4
if output_alignment:
return final_outputs, alignment[:, :i, :phone.size(1)]
return final_outputs
|