一种直接利用原始音频的语音转换系统,可实现 zero-shot 语音转换。
引言
论文链接 https://arxiv.org/abs/2106.00992
代码连接 https://github.com/sony/ai-research-code
模型优缺点:
-
模型训练是贼慢,卡少的低端玩家直接劝退。我觉着主要问题是数据增强及 Speaker encoder 模块导致的,同时 Mel-GAN 声码器建模能力相对较弱。
-
模型 GPU 推理速度贼快,全是卷积操作,省去了特征提取过程。
-
怎么能让它训练的更快,且效果更好呢?我这里想到的方法是不做 Zero-shot 这种太过于娱乐的产品,将 Speaker encoder 直接换成 One-hot 的 Speaker Embedding 特征(论文中 NVC-Net+ 已经这样做了)。同时,将 Generator 改成 HiFi-GAN 的生成器,判别器也改掉,增强判断能力。为了提升训练的速度,完全可以将模型提取到谱特征,然后利用谱特征建模。改完之后和 VITS 很像了,VITS 删除 Text Encoder 那个模块就和这个模型差不多了。
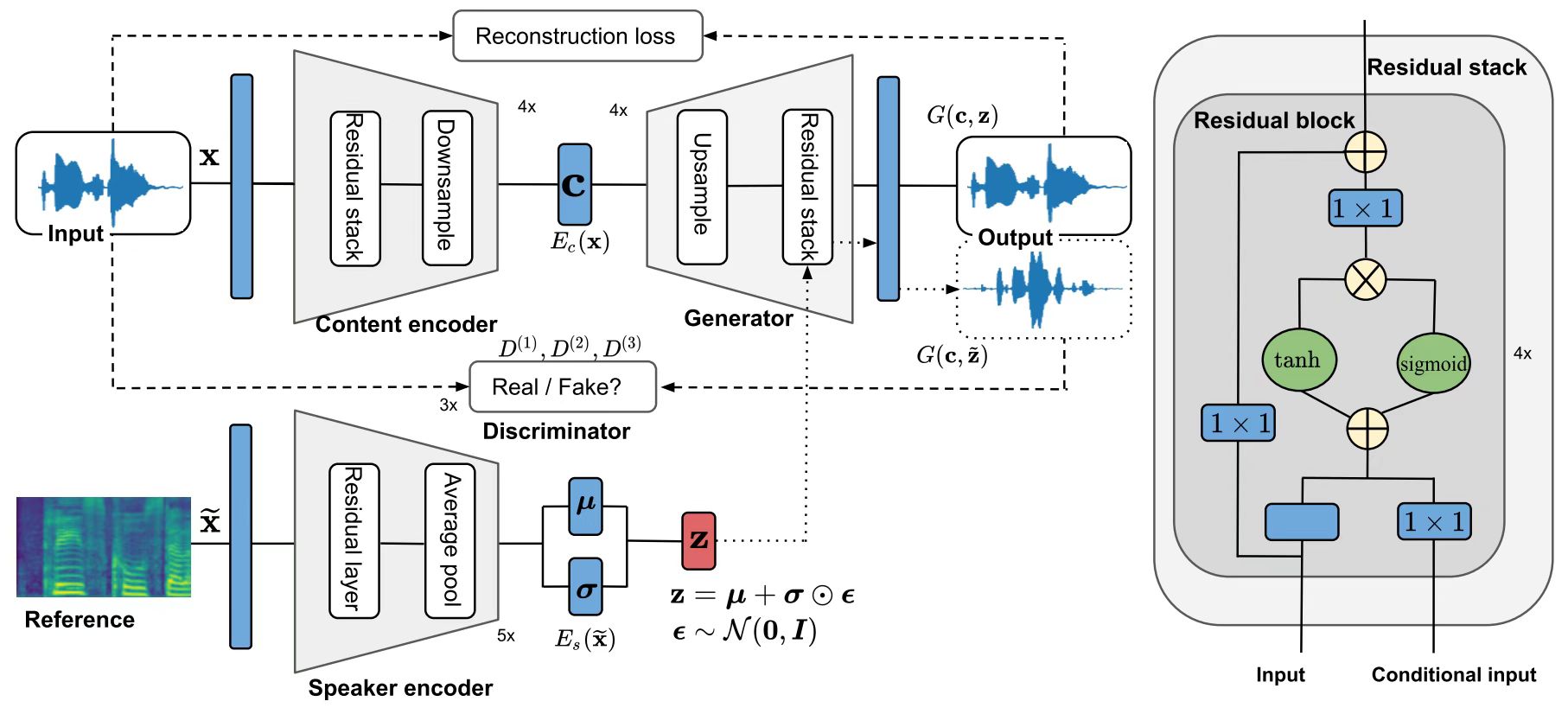
模型框架图:
代码
Content Encoder
主要过程就是下采样过程,提取音频中的 content 信息。
下采样模块主要为两个部分:第一个是膨胀卷积(不引入额外参数的前提下,可以任意扩大感受野,同时保证特征图的分辨率不变,这里引入了残差的概念,为了让网络可以更深);第二个是正常的卷积(利用stride为2,2,8,8进行下采样,同时增加通道数)。
1 | class Encoder(Module): |
1 | class DownBlock(Module): |
1 | class ResnetBlock(Module): |
Generator
主要过程就是上采样过程,根据提取的 源 content 与目标 speaker 信息,得到目标音频。主要包括两个部分:第一个是转置卷积用于上采样,第二个是膨胀卷积(这里与Content Encoder中膨胀卷积结构一样,不过在膨胀卷积之后引入了 speaker 信息)
1 | class Decoder(Module): |
1 | class UpBlock(Module): |
Speaker Encoder
根据 mel 谱获得目标说话人特征
1 | class Speaker(Module): |
Discriminator
类似与 MelGAN 的多尺度判别器
1 | class Discriminator(Module): |
1 | class NLayerDiscriminator(Module): |
训练过程
训练判别器的损失函数
- 对抗损失(交叉熵损失,真实语音为1,语音转换后的为0),使得判别器有更强的判别能力,能分辨是真实语音还是合成语音
1 | def adversarial_loss(self, results, v): |
训练生成器的损失函数
-
对抗损失(交叉熵损失,转换语音为1),使得生成器有更强的生成能力,能欺骗判别器
-
内容保存损失(真实语音经过内容编码器得到的向量和转换语音经过内容编码器得到的向量计算MSE),这里是确保内容编码器确实是得到了内容
-
kl散度损失:这里的做法其实有一些不太理解的,或者我认为这里是有问题的。既然文章说为了能从潜在空间采样,这里假设残差是服从标准正态分布的,但是为什么又直接把 speaker encoder 的后验和标准正态分布做 kl散度的约束呢?那假如这个约束力度过大,不是所有的人都得出一样的结果了吗?
-
重构损失:一个是特征匹配损失,一个是频谱损失。
训练过程中的数据增强
为了训练这个 GAN 模型,做了很多的数据增强的操作:
- 当将信号的相位移动180度时,人类的听觉感知不会受到影响,因此,我们可以通过与-1相乘来翻转输入的符号以获得不同的输入
- 随机振幅缩放
- 少量的时间抖动
- 首先,将输入信号分割为均匀随机长度为0.35 ~ 0.45秒的片段。然后,我们打乱这些片段的顺序,然后将它们连接起来,以随机顺序打乱的语言信息形成一个新的输入。我们观察到随机洗牌策略有助于避免内容信息泄露到说话人嵌入中,从而达到更好的解耦。