通过引入一个 Pluggable 的 mel decoder 来构建仅仅使用音频(没有转录文本)的 Custom Voice 系统。
论文链接https://arxiv.org/pdf/2104.09715.pdf
论文整体框架如下:
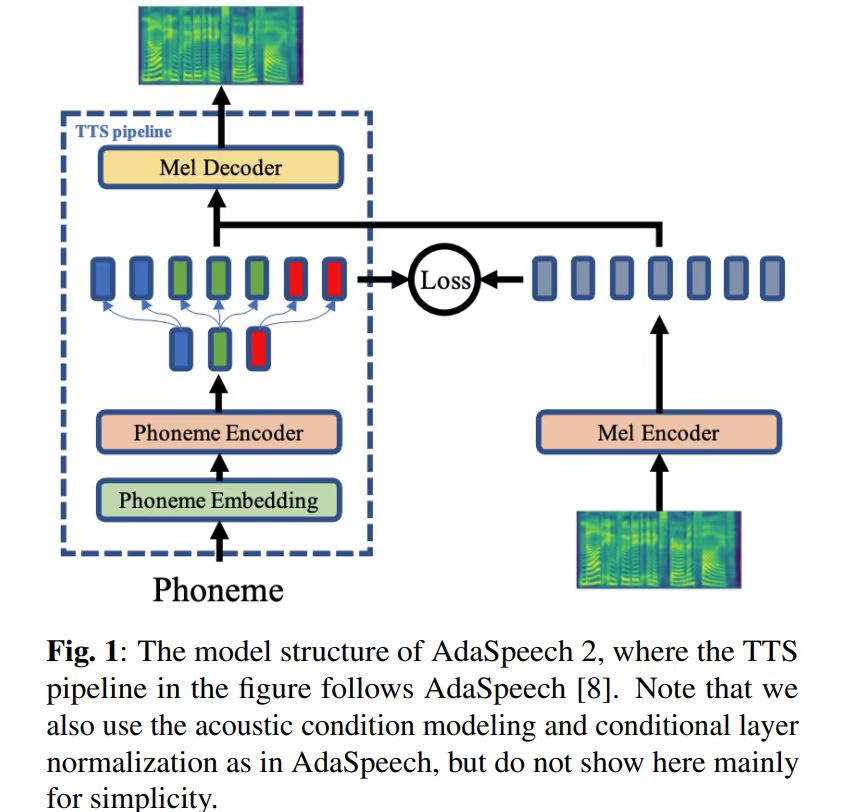
构建仅使用音频的 Custom Voice 系统分为如下四步:
1. 训练源模型
这里就是训练一个 AdaSpeech,该模型酷似 FastSpeech2, 与之不同的是 acoustic condition modeling 和 conditional layer normalization,这两个模块在 adaptation 中起了关键作用。
2. 训练 Mel Encoder
通过利用源数据进行训练,使得 Mel Encoder 的输出和已经训练好的 Phoneme Encoder 的输出尽可能的在同一个空间。注意,源数据是 <文本,语音> 成对数据。利用两个 Encoder 输出的 L2 损失进行 Mel Encoder 模型的训练。其中,为了保证模型的对称性,这里仍然用了 4 个 FFTBlocks。
3. 仅利用音频对源模型进行 Adaptation
在 Adaptation 过程中,语音通过的是 Mel Encoder, 这时的可学习参数仅仅是 Mel Decoder 中的 conditional layer normalization 层(这里与AdaSpeech是相同的)。
4. 模型推断
输入文本,通过 Phoneme Encoder,然后再通过经过 Adaptation 之后的 Mel Decoder,再结合一个鲁棒的声码器,最后获得语音。最终得到的语音的音色是与 Custom 相似的。
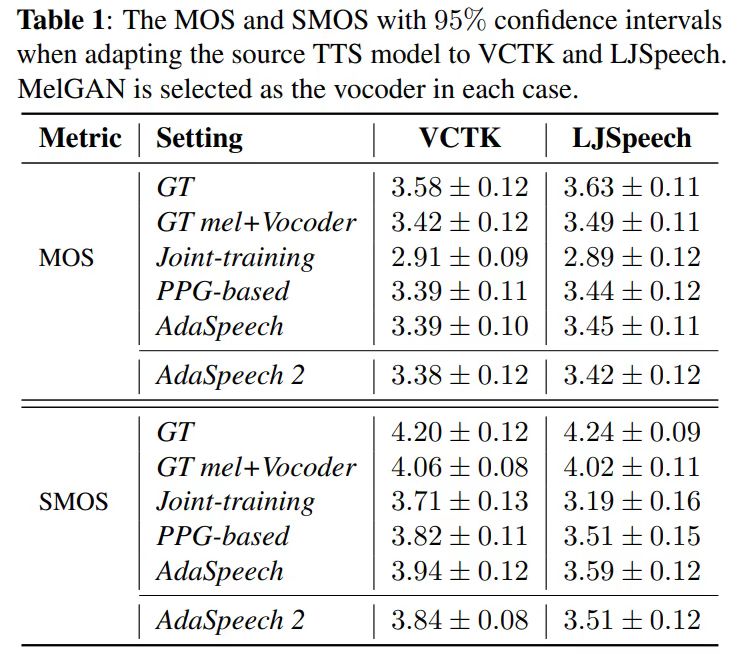
实证结果:
构建了如下四种方法进行对比
- 真实音频 GT
- 真实mel + 鲁棒的声码器
- 联合训练的方法(phoneme encoder 和 mel encoder 一起训练)
- 基于PPG的方法(将Mel Encoder 改为 PPG Encoder),PPG是语音后验图,可以理解为ASR系统中返回的每个音素的可能概率
- Adaspeech
- AdaSpeech2