VITS 基于变分推断的端到端TTS模型(融合了声学模型与声码器)
Paper
https://arxiv.org/abs/2106.06103
https://github.com/jaywalnut310/vits
VITS框架图如下:
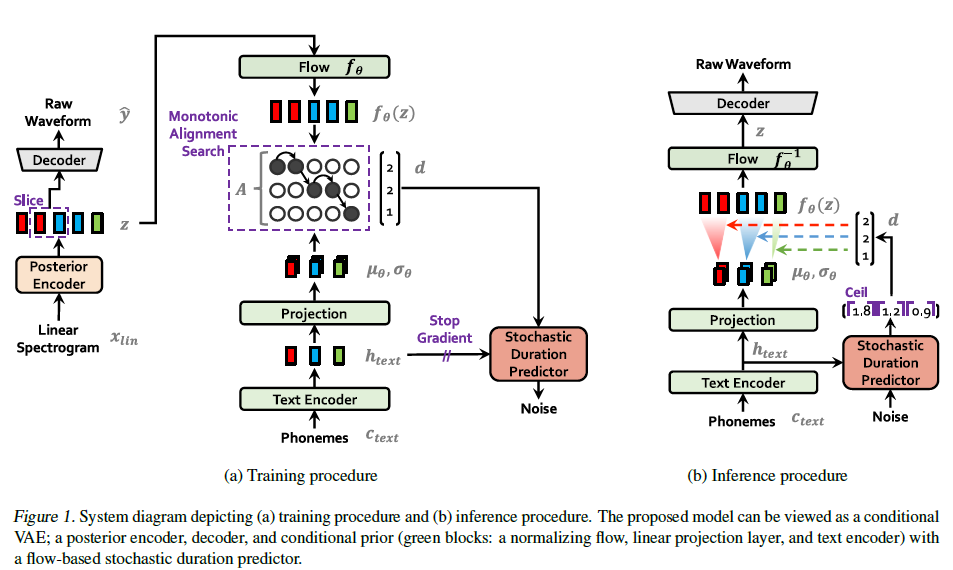
实验
中文场景(韵律嵌入)
利用中文标贝数据进行训练。
- 祝大家中秋节快乐
- 我说点什么好呢?念一个绕口令吧。八百标兵奔北坡,炮兵并排北边跑,炮兵怕把标兵碰,标兵怕碰炮兵炮。八百标兵奔北坡,北坡八百炮兵炮,标兵怕碰炮兵炮,炮兵怕把标兵碰。八了百了标了兵了奔了北了坡,炮了兵了并了排了北了边了跑,炮了兵了怕了把了标了兵了碰,标了兵了怕了碰了炮了兵了炮。
中英文混合场景
- 我刚刚去 Starbucks 买了杯 Vanilla Latte 和两块 Oatmeal Raisin Cookie, 搭配起来还蛮不错的。
- 你多吃一点 means “Have some more.” 而慢慢吃 expresses politeness to someone when eating.
- 这是一个【bad case】,共同成长。我可以读共同富裕,就是不能说共同成长.
模型及代码详解
TextEncoder
Text Encoder将 映射到 ,由6层transformer encoder构成,其中MultiHeadAttention中的n_heads为2,FFN中的kernel_size为3,这里需要注意的是 relative positional representation instead of absolute positional encoding.其中proj将映射到分布的均值与方差。
Text Encoder 参数量为 6,353,664,这个会根据音素长度的不同略有差别。
详细代码如下:
1 | class TextEncoder(nn.Module): |
PosteriorEncoder
主要的作用是将线性谱映射到分布的均值与方差,主要由non-causal WaveNet residual blocks组成,A WaveNet residual block consists of layers of dilated convolutions with a gated activation unit and skip connection.
为什么是线性谱,而不是mel谱。作者的回复是:In our problem setting, we aim to provide more high-resolution information for the posterior encoder. We, therefore, use the linear-scale spectrogram of target speech as input rather than the mel-spectrogram.
- pre:将513维利用卷积核为1的1维卷积映射到192维度
- enc:WaveNet模块,这里dilation_rate为1
WaveNet模块流程图如下:
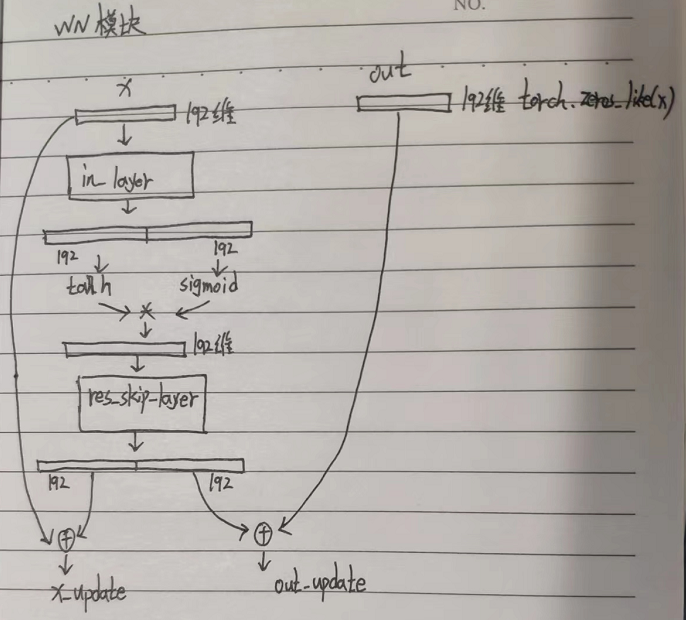
WaveNet模块代码如下:
1 | class WN(torch.nn.Module): |
- proj:将192维度映射到192*2,划分分布的均值和方差
PosteriorEncoder参数量为7,238,016.
详细代码如下:
1 | class PosteriorEncoder(nn.Module): |
Generator
将 linear spectrograms 经过 PosteriorEncoder 得到的隐变量,上采样到 wav 波形。这里的结果与 hifi-gan 中的一摸一样,唯一不同的就是 hifi-gan 是将 mel-spectrograms 上采样。详细可参考hifi-gan那篇文章。
flow
为什么要加入 flow 呢?作者是这样回复的:We found that increasing the expressiveness of the prior distribution is important for generating realistic samples. 可以简单理解为将正态分布映射到一个更复杂的分布。
flow模块总共的参数量为 7,102,080。
ResidualCouplingBlock由ResidualCouplingLayer和Flip构成。
该模块流程图如下:
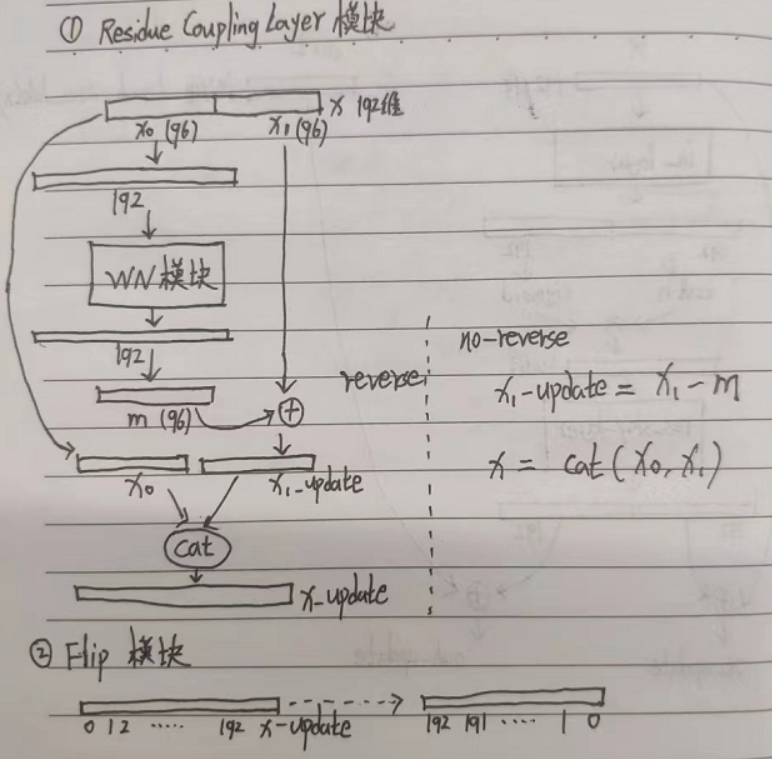
详细代码如下:
1 | class ResidualCouplingBlock(nn.Module): |
ResidualCouplingLayer模块
1 | class ResidualCouplingLayer(nn.Module): |
Stochastic Duration Predictor
为啥引入这个模块呢?
为了更好的提高语音合成的表现力,解决 one to many maping 的问题。
主要包括两个部分:
- stack residual blocks with dilated and
depth-separable convolutional layers,同时用到了残差、分组、膨胀。 - neural spline flows
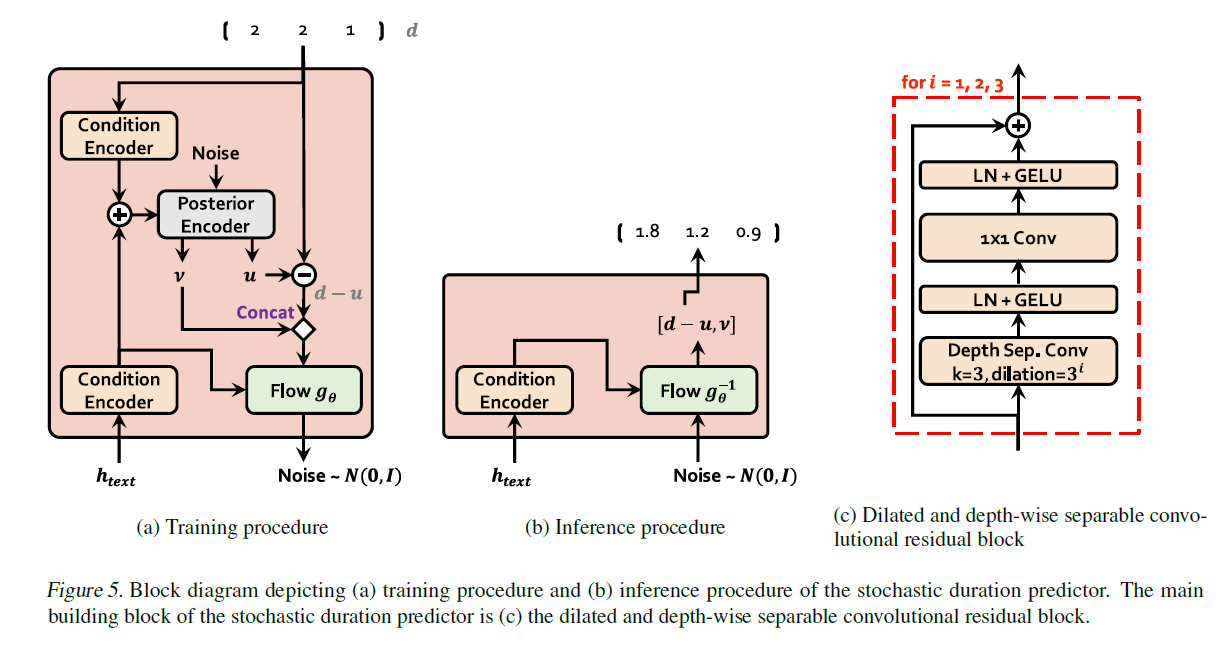
1 |
|
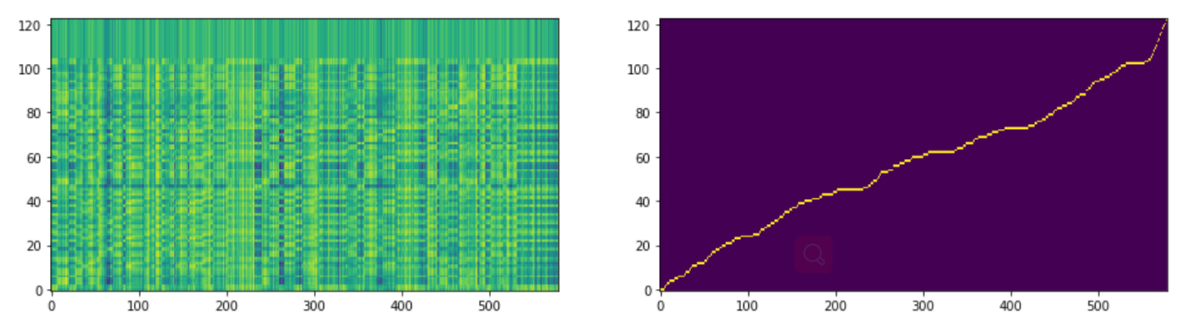
Monotonic Alignment Search
最早是Glow-TTS提出来的方法(和VITS是同一个作者),目的省去额外对齐的过程。
- 计算似然矩阵
1 | with torch.no_grad(): |
- 根据似然矩阵得到对齐路径(动态规划算法,可以参考DTW理解)
1 | import numpy as np |
左图为似然矩阵,右图为对齐结果
切片训练
这里不是整个音频进行对抗训练的,而是进行了随机切片处理。hifi-gan也是这样的。segment_size=8192,大约是0.37秒。
对抗训练
与 hifi-gan 很类似,鉴别器还是多周期鉴别器(多周期和hifi-gan中一样) + 多尺度鉴别器(多尺度这里就用到了一个)。
- 损失函数
与 hifi-gan 不同的就是损失函数新增了先验和后验的KL散度
1 | def kl_loss(z_p, logs_q, m_p, logs_p, z_mask): |