摘要
PortaSpeech:Portable and High-Quality Generative Text-to-Speech
Paper
https://arxiv.org/abs/2109.15166
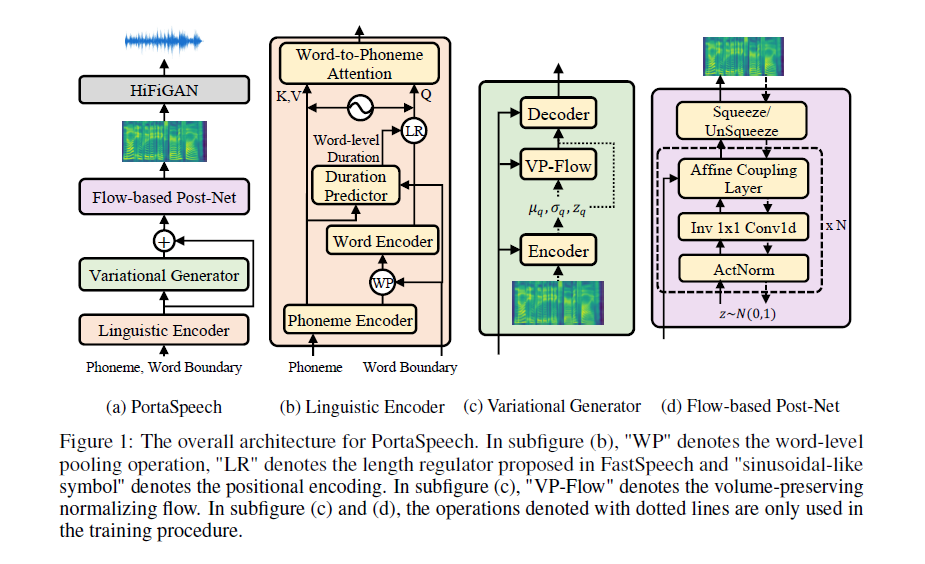
论文的出发点:
- VAE模型擅长捕捉长范围之间的语义特征(如韵律),但是结果会 blurry (mel谱会模糊掉) 和 unnatural.
- normallzing flow 能够较好的重构mel谱的细节,但是在模型参数量有限的情况下表现较差
论文的核心方法:
- 轻量级VAE建模韵律,基于flow的后处理网络增强mel谱的细节表达
- 为了压缩模型大小,将基于flow的后处理网络中的affine coupling layers引入了分组参数共享机制
- 为了提高TTS的表达能力,将原来音素级别的hard-alignment改变为词级别的hard-alignment,词级别到音素级别利用attention进行soft-alignment.
这里利用Praat看一下音素级别hard-alignment的问题:
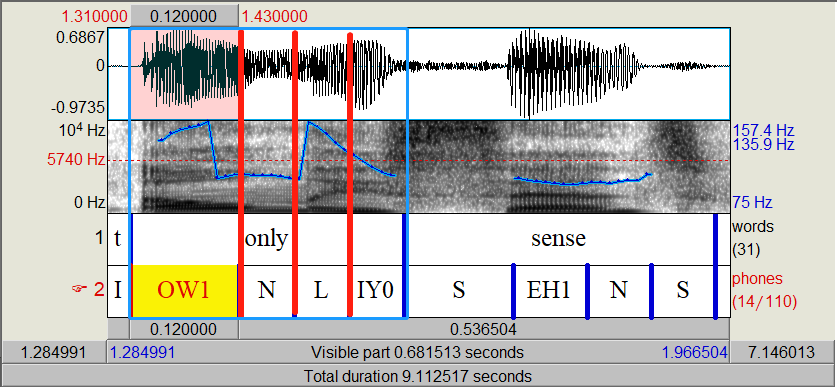
利用词级别能改善,但是也会存在问题:
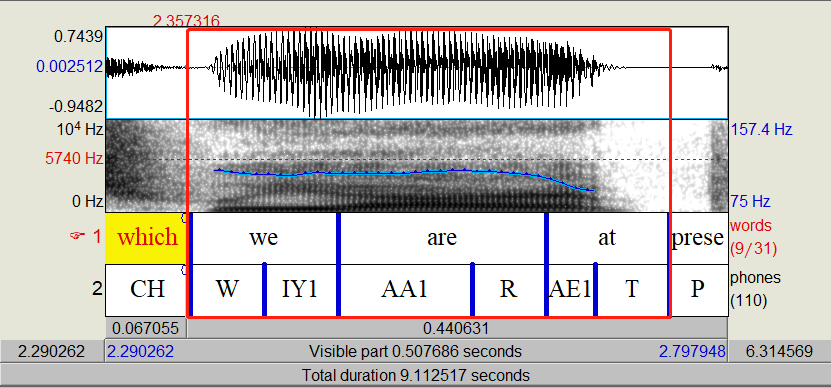
利用句子级别可能会更好,但是存在鲁棒性降低的风险。
代码详解
https://github.com/NATSpeech/NATSpeech该代码使用 pytorch框架
Text Encoder 模块
-
phoneme Encoder(FFT blocks), 将输入的音素编码到隐状态[1, 128]维向量,如果存在多说话人,在这里可以加入 speaker embedding,或者 emotion emdedding
-
将音素级别的 hidden state 转换为 word 级别,利用 word 与 phoneme 的对应关系,将一个 word 中音素的 hidden state 求平均即可获得 word 级别 hidden state(论文中命名为word leval pooling operation, WP)
-
word Encoder(FFT blocks), 将第2步生产的 word hidden state 再经过几个fft进行编码
-
将第1步得到的 phoneme 级别的 hidden state 经过 Duration Predictor,获得音素级别的 duration;利用 word 及 phoneme 的对应关系,将 phoneme 级别 duration 进行求和,获得 word 级别的 duration
-
通过 LengthRegular 机制将 word 级别 hidden state(第3步结果) 根据 word duration 进行expand [batch_size, mel_T, hidden_size]
-
Attention:
6.1. 第1步获得的 phoneme hidden state 与位置编码 cat,经过线性层将维度映射到原来的 hidden size. 生成 K and V(两个是一样的).
6.2. 第5步获得的经过 expand 的 word hidden state 与位置编码cat,经过线性层将维度映射到原来的 hidden size,再经过一个文本后处理层,得到最后的 Q
6.3. 这里有 attn_mask,确保attn的是单词对应到本单词的音素。
6.4. 输出 x 和 attention weight 结果,这里又利用了残差网络的思路,将 x 和 第6.3步的Q进行了相加
1 | def run_text_encoder(self, txt_tokens, word_tokens, ph2word, word_len, mel2word, mel2ph, style_embed, ret): |
Dencoder 模块 (FVAE)
输入:Text Encoder 获得的结果
输出:Mel spectrogram
-
pre-net,将 text Encoder 的结果经过 pre-net 处理,类似于瓶颈层,维度变换[1, 128, 812] --> [1, 128, 203]; 这里进行的是一维卷积操作,卷积核大小 8, 步长为4,padding 为2,(812 + 2*2 - 8)/4 + 1=203
-
VAE-Encoder, 将 mel spectrogram 与 condition 编码到 mean 和 sigma(这里用了log方差,为啥这样呢,因为方差都是非负数的,取log就不用特别设计激活函数了)
-
在VAE引入了prior_flow,由于单纯的正态分布过于简单,这种约束下生成模型的多样性会降低,prior_flow的作用是把正态映射到一个更复杂的分布
-
VAE-Decoder, 利用第2步的输出与condition对mel spectrogram进行重构.
1 | class FVAE(nn.Module): |
Post_Glow 模块
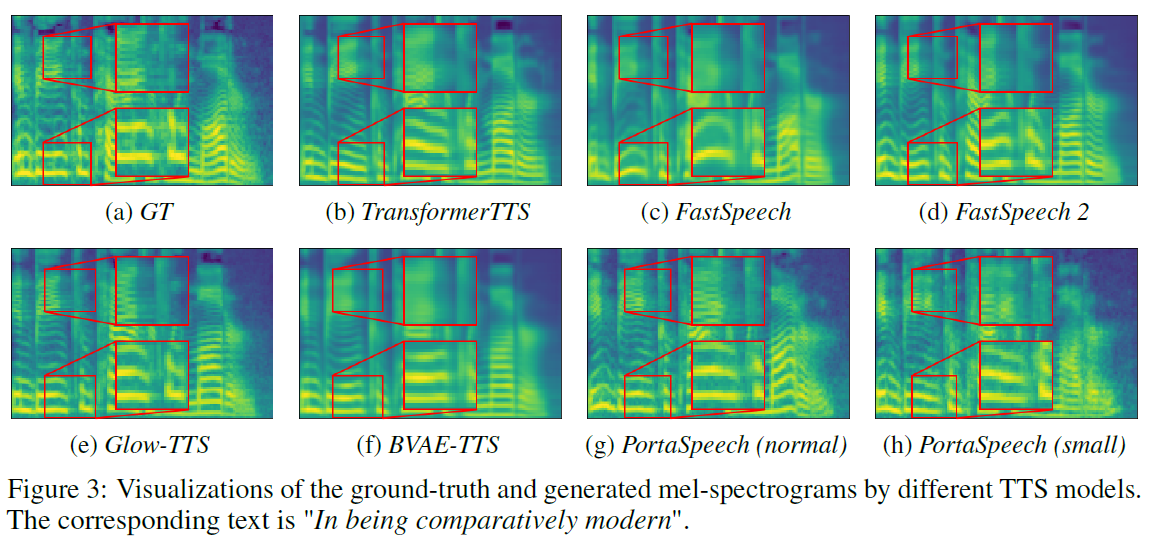
基于 normalizing flow 的后处理网络,由于VAE合成出来的是比较 blurry 的mel谱图,可以看如下的结果对比,利用 flow 后处理网络可以获得更优的细节表现,可以理解为 Tacotron2 的post-net的作用,不过基于 flow 的更好。
传统 flow 必须需要大量参数才能获得更好的结果,作者在 Affine Coupling Layer 加入了参数共享机制,缩小了模型。
关注到代码中 Post_Glow 是单独训练的,detach()之后,阻断了通过损失函数反向传播修改参数。
Glow 的更多细节可参考如下文章及博客:
损失函数包含如下四个部分:
- word level duration loss, MSE, log scale;
- VAE 中的重构损失,MAS
- VAE 中的分布约束损失,KL-divergence
- Post-Net 的非负对数似然