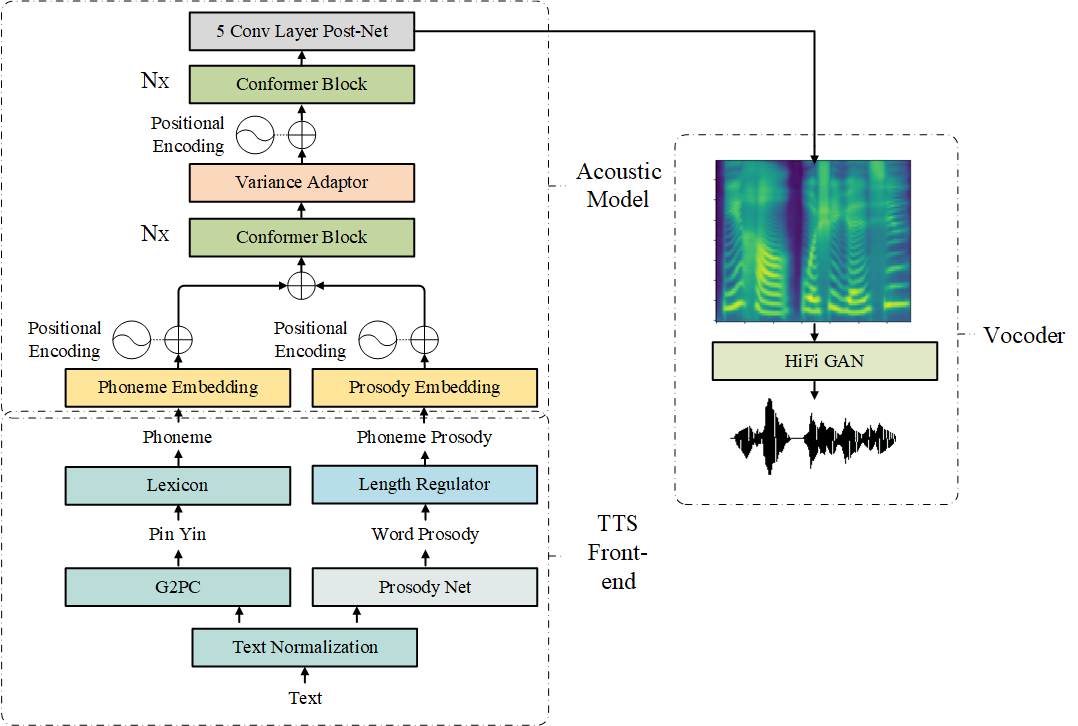
音素级别hard duration及低资源这两个痛点,导致FastSpeech2模型的韵律表现不太好。但由于其鲁棒性高,我这里想将文本信息加到里面,利用大量文本信息先构建韵律边界(PW,PPH,IPH)的预测模型。再通过Length Regular机制将韵律边界映射到音素级别,从而提高TTS的韵律。
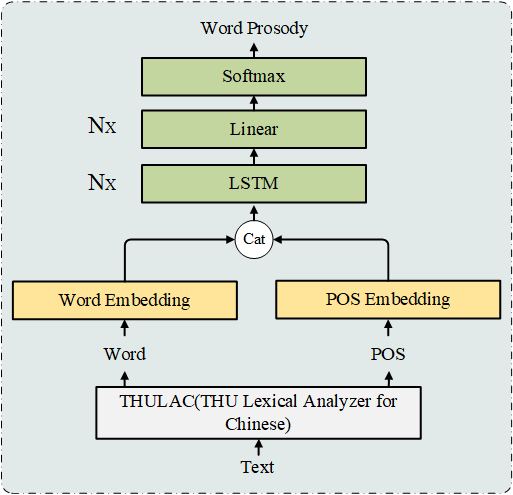
这里的韵律边界预测可以定义为TTS的前端模型,这里可以堆一个BERT,但是这个模型太大,不利于部署及实时推断。这里构建了一个小型的网络。
整体TTS框架流程图如下:
韵律预测框架图如下:
整体的这个想法是在参加新网银行2021TTS挑战赛想出来的,比赛答辩PPT及音频示例见notion
少部分示例如下:
- 示例1
002 目前申请好人贷支持身份证原件实时拍摄或上传相册照片两种方式,但复印件及临时身份证是不可以的哟。
原始FastSpeech2模型
增加韵律的FastSPeech2模型
Tacotron2模型