语音转换综述
引言
一般来说一个 speaker 可以用三个特征来表征:
- linguistic factors:语言学特征,如句子结构、词、方言等信息
- supra-segmental factors:超音段特征,如韵律
- segmental factors:音段特征,如频谱和共振峰
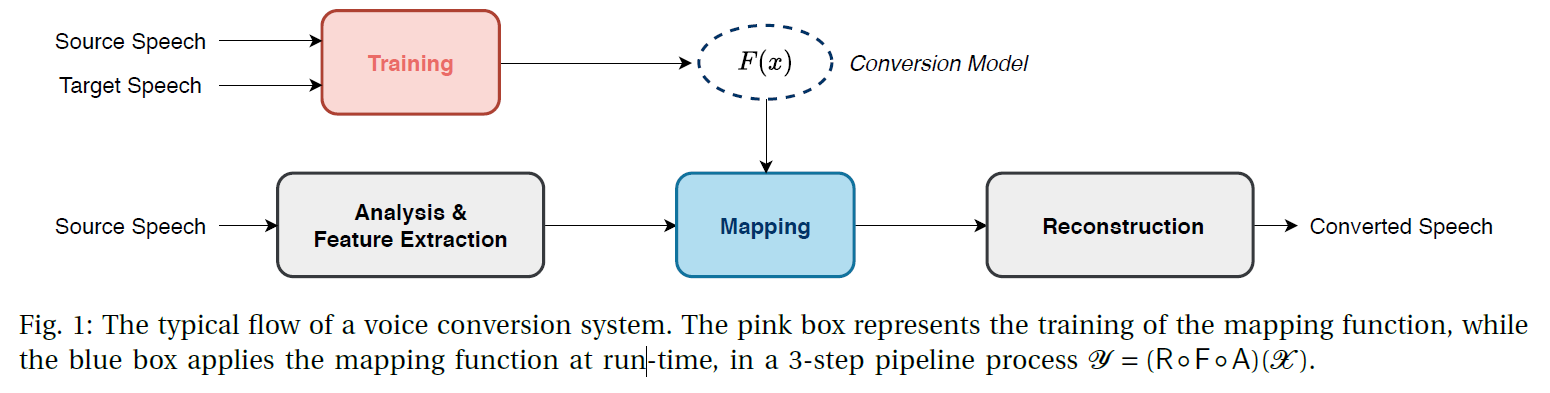
传统语音转换的技术实际上就是对 supra-segmental 和 segmental 的转换。典型的语音转换(Voice Conversion)的 pipeline包含了如下三个部分:
- speech analysis:提取 source speaker 的 supra-segmental 和 segmental 的信息
- mapping:将 source speaker 的 dupra-segmental 和 segmental 转换为 target speaker 的
- reconstruction:结合 source speaker 的 linguistic 进行重构
深度学习语音转换可以实现端到端,但很多网络结构的设计也都借鉴了传统的方法。
传统的语音转换
语音分析及重构技术
- Signal-based Representation:
- PSOLA: Pitch Synchronous Over-Lap and Add
- HNM: Harmonic plus Noise Model
- Model-based Representation:
- source-filter model
参考
An Overview of Voice Conversion and its Challenges: From Statistical Modeling to Deep Learning