HiFi-GAN:有效的、从 mel-spectrogram 生成高质量的 raw waveforms 模型。主要考虑了“语音信号是由不同周期的正弦组成”,在 GAN 模型的 generator 和 discriminator 分别利用了这一点,对音频的周期模式进行建模,从而提高了合成质量。
Paper
https://arxiv.org/abs/2010.05646
genertor框架图如下:
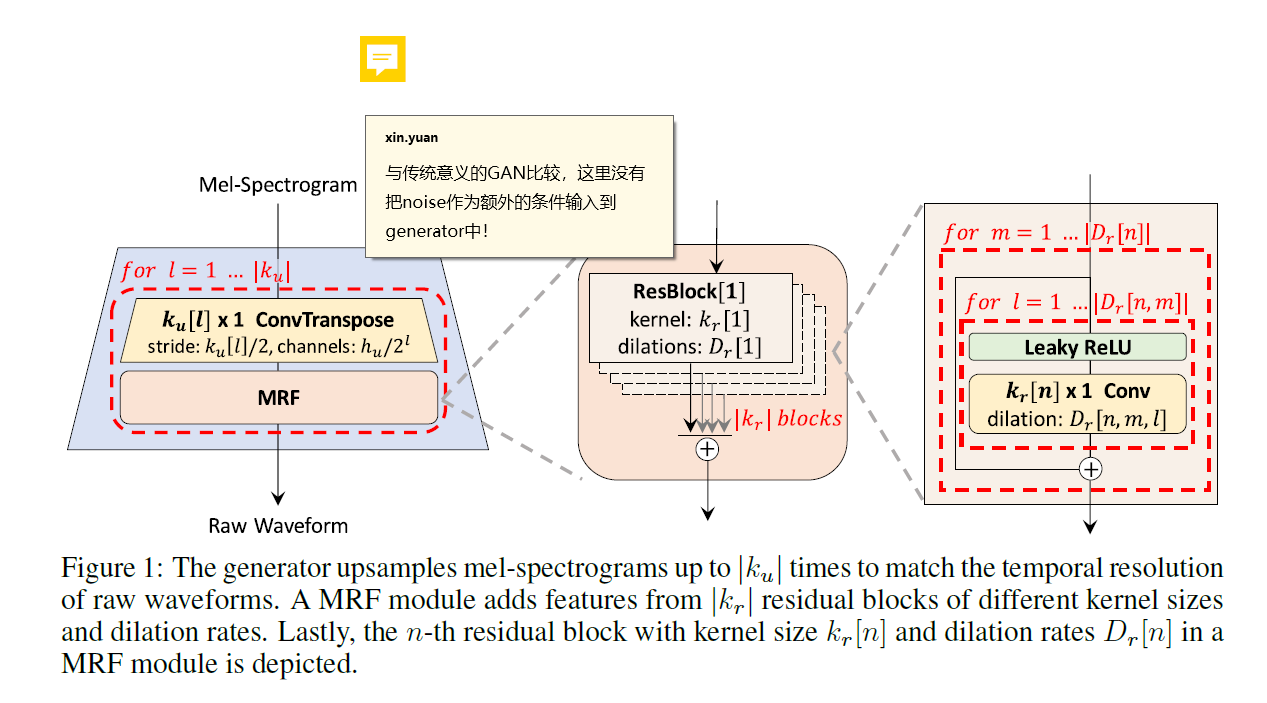
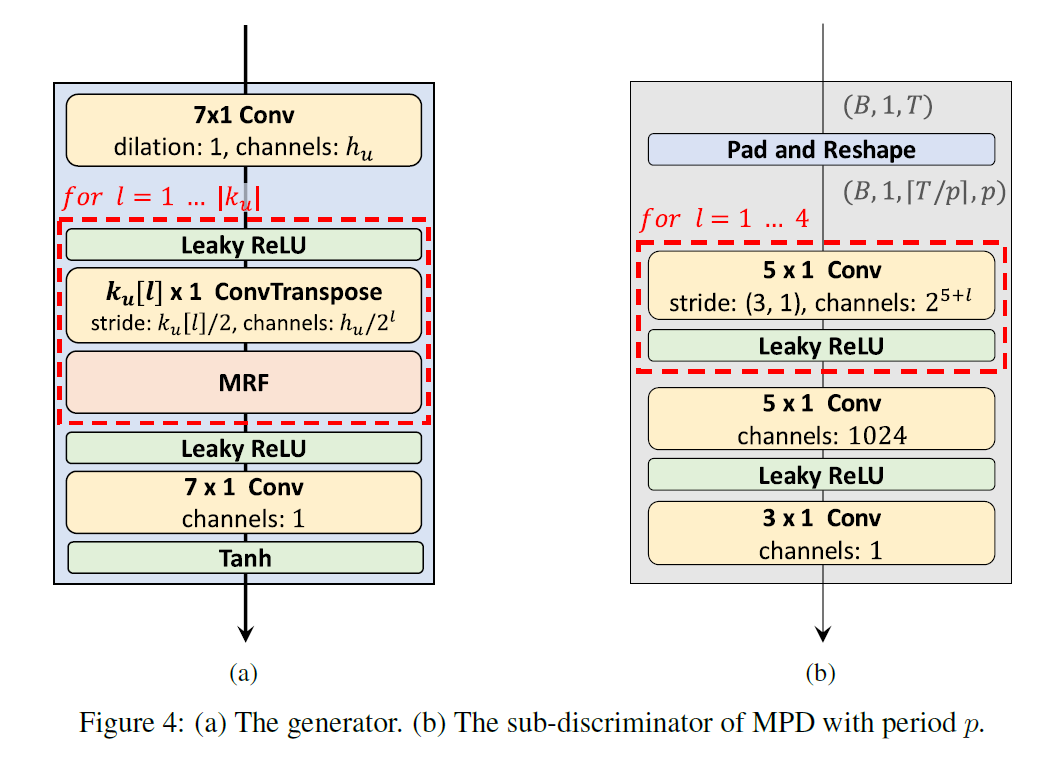
discriminator框架图如下:
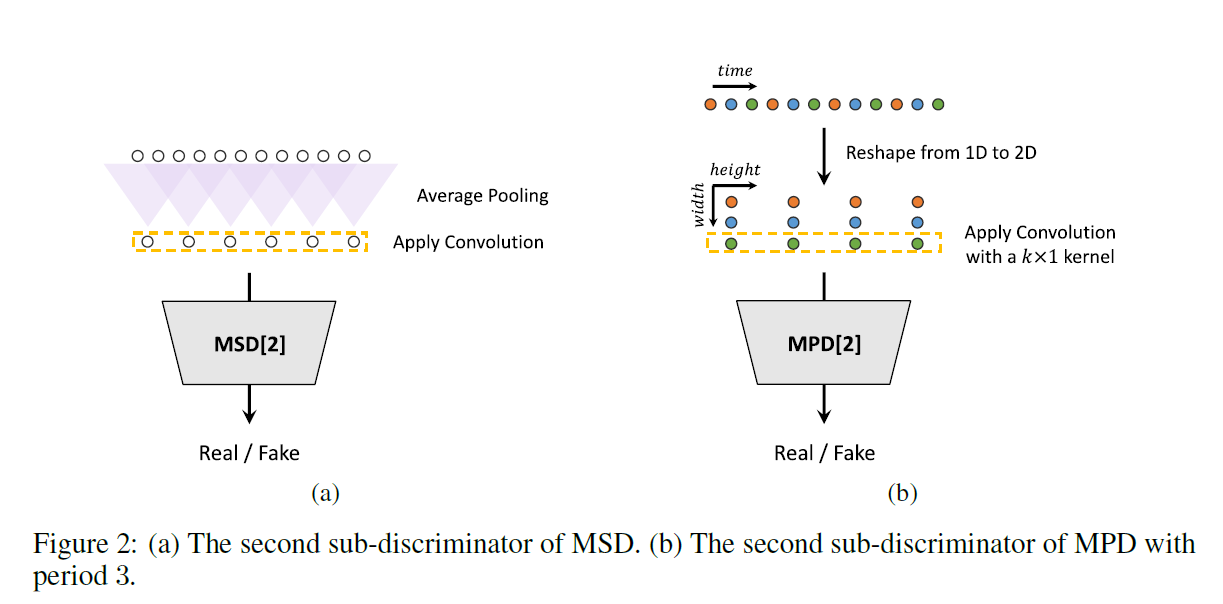
代码
https://github.com/jik876/hifi-gan 官方代码
生成器 Genertor
在详细解释 genertor 之前先介绍转置卷积及膨胀卷积这两个衍生的卷积操作。
转置卷积(Transpose Convolution)在语义分割或者对抗神经网络(GAN)中比较常见,其主要作用就是做上采样(UpSampling)。详细介绍可参考大佬讲解视频李沐–47 转置卷积【动手学深度学习v2】
转置卷积维度变化公式为:
out_dim = (in_dim - 1) * stride - 2 * padding + kernel_size;这个公式正好与卷积相反
膨胀卷积
在不引入额外参数的前提下可以任意扩大感受野,同时保持特征图的分辨率不变。注意设置合理的膨胀系数避免出现 Gridding Effect。
膨胀卷积维度变化公式为:
out_dim = (in_dim + 2 * padding - (kernel_size - 1)*dilation - 1) / stride + 1
当想要维持输入输出维度不变时,即same padding,padding的参数计算为:
1 | def get_padding(kernel_size, dilation=1): |
- genertor
生成器全部由卷积构成,主要分为如下几个部分:
- conv_pre:1维卷积,将 80 维的 mel 谱图映射到 512 维;
1 | conv_pre = weight_norm(Conv1d(80, h.upsample_initial_channel, 7, 1, padding=3)) |
-
ups:上采样模块,由转置卷积 ConvTranspose1d 组成,上采样分为4个卷积:卷积核大小 16, 16, 4, 4;Stride大小(同时也是上采样率) 8, 8, 2, 2;channels 变化 512–>256–>128–>64–>32。最后会得到将[512, T]维度的特征映射到[32, T*256]维度的特征;这里放大256倍正好符合当时mel谱生成过程中hop_size=256!
-
resblocks:论文中提到的MRF(Multi-Receptive Field Fusion),利用膨胀卷积中不同卷积核大小和不同的膨胀率来生成不同感受野的输出。resblocks共有3个resblock,卷积核大小分别是[3, 7, 11],膨胀率分别是[[1, 3, 5], [1, 3, 5], [1, 3, 5]]。具体过程如下:
1 | # 1. 每个 ups 上采样模块之后都接了一个 resblocks; |
- conv_post:将 32 维特征映射到 1 维度
- tanh:将值映射到【-1, 1】,正好对应音频点 【32768,32767】
整个生成器genertor详细代码如下:
1 | class Generator(torch.nn.Module): |
生成器损失函数
- L1 distance 的 Mel-Spectrogram Loss, 权重系数为 45
- L1 distance 的 Feature Matching Loss(判别器特征的对比,MPD和MSD),权重系数为 2
- 原有 LS-GAN 的损失,好多个子鉴别器损失求和
判别器 Discriminator
multi-period discriminator (MPD)
由于语音信号很长,100ms就要有2200个采样点,高采样率的更多,所以识别长期依赖关系是模拟真实语音的关键。MPD主要的出发点是由于语音音频由不同周期的正弦信号组成,需要识别音频数据中的不同周期模式。MPD共包含五个子鉴别器(主要就是periods 参数不一样),periods 为[2, 3, 5, 7, 11]。
MPD单个子鉴别器构建的过程如下(上文中的图可以很好的表示清楚):
- 按照period将原始1D波形变为2D数据;
- Conv2d,增大channels,降低 t(时间维度)
- fmap:记录各个卷积输出特征,用于后续训练生成器
维度变化为:
1 | segment_size = 8192 # 表示仅仅利用 wav 中 8192 个点 |
单一MPD代码如下:
1 | class DiscriminatorP(torch.nn.Module): |
整个判别器MDP代码如下:
1 | class MultiPeriodDiscriminator(torch.nn.Module): |
- 判别器损失
这里损失函数并不是原始GAN论文里的交叉熵损失,而是利用了LS-GAN中的优化函数,求的是最小二乘损失。直观理解,真实值为1,生成值为0。在固定G优化D的过程中,使得越小越好,即能更好的区分生成和真实;在固定D优化G的过程中,使得越小越好,即生成的越来越接近1。
鉴别器损失函数计算如下:
1 | def discriminator_loss(disc_real_outputs, disc_generated_outputs): |
multi-scale discriminator (MSD)
由于MPD鉴别的都是不连续的采样点,故引入MSD来进行辅助,MSD主要是MelGAN提出来的。MSD is a mixture of three sub-discriminators operating on different input scales: raw audio, *2 average-pooled audio, and *4 average-pooled audio.
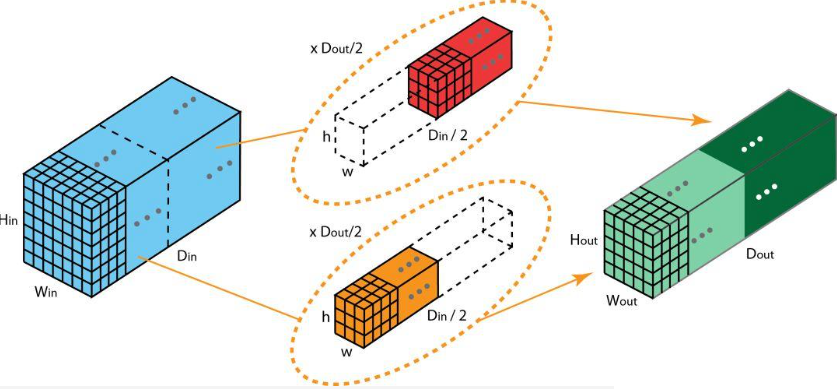
这里需要介绍 Grouped Convolutions
groups controls the connections between inputs and outputs. in_channels and out_channels must both be divisible by groups. For example,
-
At groups=1, all inputs are convolved to all outputs.
-
At groups=2, the operation becomes equivalent to having two conv layers side by side, each seeing half the input channels and producing half the output channels, and both subsequently concatenated.
单一MSD为
1 | class DiscriminatorS(torch.nn.Module): |
整个MSD代码如下:
1 | class MultiScaleDiscriminator(torch.nn.Module): |
Fine-Tuning
待续