摘要
问题:怎么根据单一语种数据,构建双语或者是Code-Switched的TTS。
解决方案:利用VC进行数据增强,然后再强行将两个语种的数据堆到一个TTS模型就可以
这篇文章是阿里提出的,详细地址https://arxiv.org/abs/2010.08136v1
这里我利用Data Baker中文开源TTS数据集Chinese Mandarin Speech Synthesis Datasets进行了尝试。结果如下:
- 原始声音(卡尔普#2陪外孙#1玩滑梯#4)
- 说英文(in being comparatively modern.)
- 说中英文混合(你多吃一点 means “Have some more.” 而慢慢吃 expresses politeness to someone when eating.)
背景
双语语料获取比较难。
解决方法
古人就有研究过,利用一个ASR系统,将ASR系统得到的senones(可以理解为类似音素的单元)用来构建双语之间的映射关系,从而构建双语TTS系统,不过当时还是HMM打天下的年代,合成效果不是很好。
本文作者核心的做法就是把HMM换成了现在比较流行的Tacotron2模型。
语音转换系统
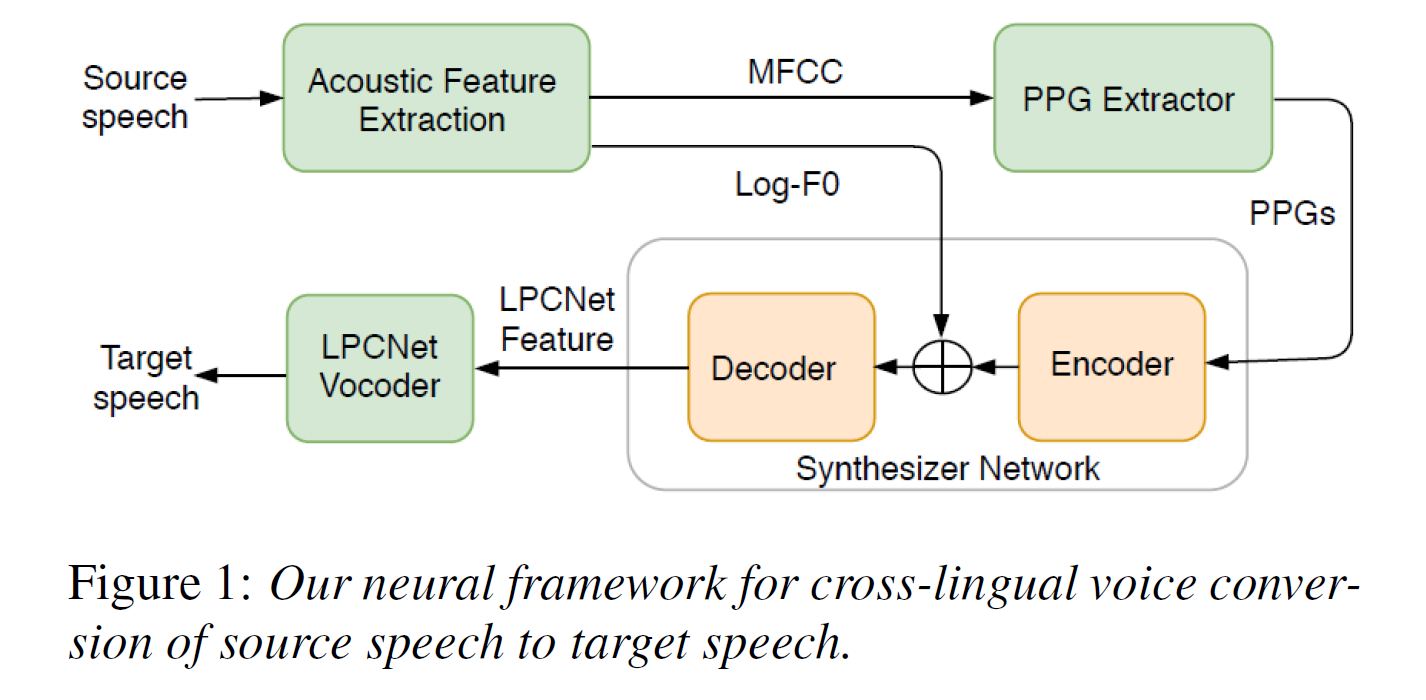
具体步骤如下:
-
首先,需要训练一个PPG Extractor(这个可以理解为ASR的声学模型),最后根据这个提取器获得是PPG(Phonetic PosteriorGram, 语音后验图),表示的就是对应帧可能是每个音素的概率。
这里仅仅利用了中文 AISHELL-1训练 PPGs提取器。可以这样理解:为的是输入数据分布相同。假设我们利用中文音素提取中文语音,英文音素提取英文语音。这样在后续tacotron2中输入的就是不同分布的!恰好是仅利用中文训练的PPGs,从而构建了双语之间的映射关系 -
训练两个语言的TTS模型(输入为PPGs和log-F0,输出为LPCNet Feature)。这里log-F0还是很关键的,它放到了TTS模型的Encoder和Decoder之间,保证了在语音转换过程中不会改变语音的韵律及节奏。
-
开始进行语音转换,例如:把英文语音(source speech)输入到 PPGs 提取器,然后再把PPGs和log-F0输入到中文语音(target speech)的TTS模型中,这样target 就会说英文了。
构建双语TTS模型
这里已经获得了单语言说话人的双语数据了。我们这里需要做的就是把双语语料放到一起来学习同一个模型。这里需要注意的是,中文音素和英文音素需要映射到不同的token。例如中文TTS中音素为200个,英文音素为80个,最后双语模型的音素就应该是280个。
-
一些实验经验:
FastSpeech2模型构建的双语及Code-Switched TTS 相较于 Tacotron2 更稳定,我猜测是这样的原因:Tacotron2的Decoder是LSTM结构,自己体会。 -
一些想法:
构建双语TTS还可以利用迁移学习,首先利用少量语料进行迁移学习,进而进行数据增强。