摘要
声纹识别:主要是通过声音来识别人的任务。主要的子任务有 speaker verification(说话人验证)、speaker identification(说话人识别)和 speaker diarization(从多说话人语音中分离成单个说话人的语音片段)。下图可以很好说明
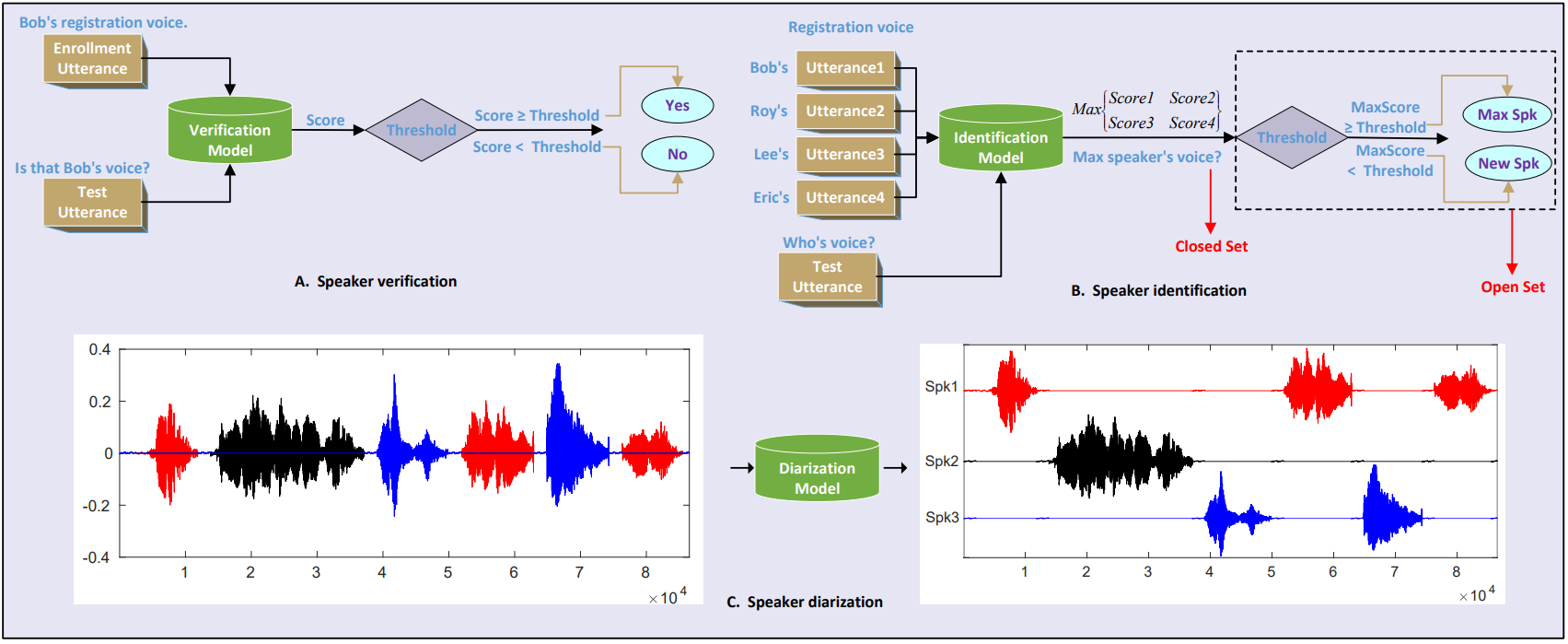
引言
声纹识别主要利用了说话人声音里的个人特征,这些个人特征主要是由于独特的发音器官和说话方式导致的,例如声道形状、喉咙大小、口音和韵律等。
声纹识别主要的应用场景有:个人智能设备(如电话、汽车、笔记本)的基于语音的身份验证;银行交易、远程支付;侦察犯罪嫌疑人;还可以作为ASR的前端,提高多说话人对话的转录性能。
经典的模型:Gaussian mixture model based universal background model (GMM-UBM) 前端模型 (用于提取说话人特征) + probabilistic linear discriminant analysis (PLDA) 后端模型(用于计算提取特征的相似度)
目前的模型:deep neural networks (DNNs)