摘要
Custom Voice:目的是采用源TTS模型来合成目标说话者的个人声音,而目标说话者只有少量的讲话。
存在的挑战:
-
为了适用不同的说话者,建立的模型需要处理不同的声学条件,这些条件可能与源语音数据非常不同,如说话的韵律,风格,情感,口音,以及录音环境。
-
为了支持大量的说话者,适应参数需要足够的小。更多的适应参数通常会导致更好的语音质量,但是会增加内存容量和服务成本,举个例子,云语音合成支持100万用户,如果定制语音需要100M大小,则总内存存储大约为100PB,这是一个相当大的服务成本。
论文提出的方法:
-
为了处理不同的声学条件,对语音信息和音素信息进行了建模
-
为了更好地权衡自适应参数和语音质量,在Mel谱解码器中引入了条件层归一化
实证研究:
-
源声音数据(LibriTTS datasets)
-
目标声音数据(VCTK和LJSpeech,仅20句约1分钟的时间)
MOS和SMOS评价
Demo:https://speechresearch.github.io/adaspeech/
引言
发展现状:目前针对单人大量语料的情况下可以合成很自然,流畅的语音;同时,也拓展到了多说话人的场景。但是,这些语料库包含一组固定的说话者,其中每个说话者仍然有一定数量的语音数据。
- 前人的研究:
- fine-tune整个模型
- fine-tune decoder part
上述两个改进的效果已经很好了,但是缺陷就是更新的参数太多,很多用户用的话,成本高。
- fine-tune the speaker embedding
- train a speaker encoder module
上述两个更新的参数少,但是效果不是很好。
模型
模型有以下三步组成:
-
pre-training:通过多说话人数据集预训练TTS模型,这样有助于之后adaptation
-
fine-tuning:在不同的acoustic conditions下微调模型或者模型的一部分
-
inference:推断
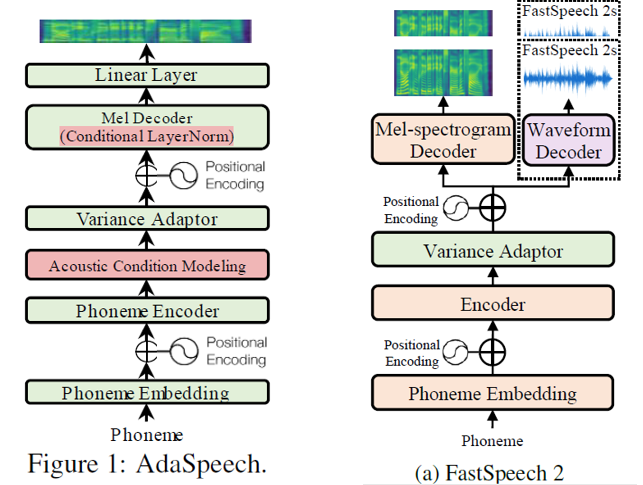
模型是在non-autoregressive TTS models FastSpeech2的基础上改进的,改进点如下:
- Acoustic condition modeling:
在预训练与微调中都加入了这个声学条件建模,分为两个小部分,都是acoustic encoders。
- an utterance-level vector(全局声学条件)
- a sequence of phoneme-level vectors(局部声学条件)
以上两个条件输入到Decoder预测Mel谱。这样的话就可以通过修改不同人的声学条件,从而达到Custom Voice的目的了。
- Conditional layer normalization
- by using speaker embedding as the conditional information to generate the scale and bias vector in layer normalization
- 在fine-tuning中,仅更新Conditional layer normalization中的参数
- adaspeech 与 fastspeech2对比如下: